文章首发我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
没错,这个标题就是个标题党,目的就是为了让你点进来看看。
2017 年是人工智能元年,我们也能看到各大互联网公司对于人工智能的大布局。但人工智能再怎么牛逼,别忘了它的底层基础设施是什么,没错,就是云计算,少了云计算的底层支撑,人工智能也只能活在书本里。虽然说云计算经过这么多年的沉淀,技术总体上来说已经比较成熟,但有一门技术仍然呈现欣欣向荣之势,未来发展仍有无限可能。
它就是以 docker 为首的容器技术。
不知道大家关注最近这两天的 KubeCon 2017 北美峰会没有,会上提得最多的也是容器技术,其中最大的新闻莫过于 OpenStack 基金会发布了最新开源容器项目 Kata Containers。看到这个消息,我的第一反应是「为啥最近容器圈的动作这么多」。
我们把时间拉回到 11 月底的中国开源年会上,当时阿里正式开源了自家自研容器项目 Pouch。再把时间拉到差不多两个月前(10月17日)的 DockerCon EU 2017 大会上,彼时 docker 官方宣布全面支持 kubernates。类似这样大大小小的动作,在 2017 年还发生了很多,这一切的动作都在说明容器的重要性,未来的可期待指数可以说不亚于人工智能。
下面简单介绍下 Kata 和阿里的 Pouch 到底是个怎样的角色,我也仅限于网络上各种资讯的了解,信息传达难免会有失误,如果大家觉得有问题可以留言指出。
Kata Containers 是什么
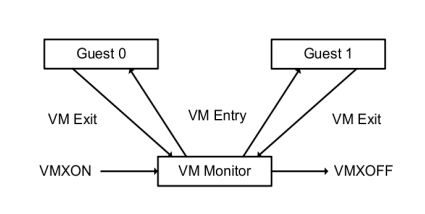
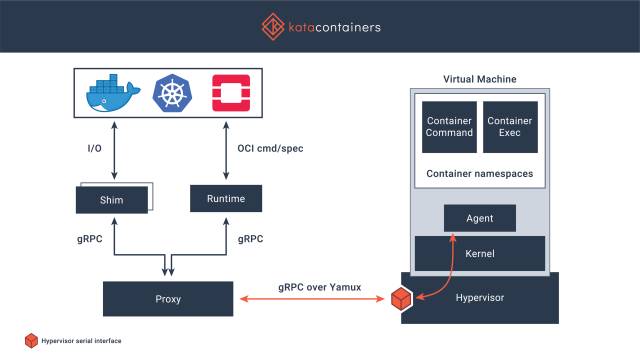
Kata 官方宣称这是同时兼具容器的速度和虚拟机安全的全新容器解决方案,旨在将虚拟机的安全优势与容器的速度和可管理性统一起来,其建立在 Intel 的 Clear Containers 技术和 Hyper 的 runV 虚拟机管理程序运行时基础之上。

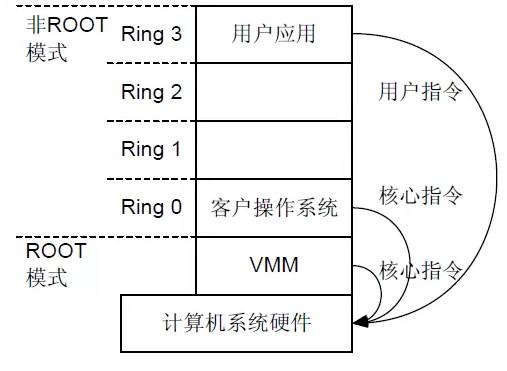
Kata 的特点是什么?总体来讲,Kata 解决的是容器的安全问题。众所周知,当前容器技术旨在实现在一个虚拟机之上运行多个用户的、多个应用的容器实例,不同实例之间共享同一个虚拟机操作系统内核并采用 Namespaces 来隔离,但这种方式很难保证各实例彼此之间的完全隔离,存在安全隐患。
Kata 的解决方案是意图为每个容器实例提供一个专属的、高度轻量化的虚拟机操作系统内核来解决这个问题。让某一个用户的、一个应用的一个或多个容器实例单独跑在这个专属的虚拟机内核之上,这样不同用户、不同应用之间都是使用独占的虚拟机,不会共享同一个操作系统内核,这样就确保了安全性。
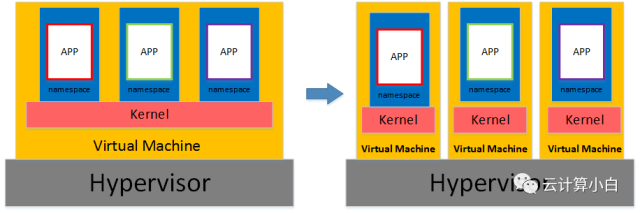
另外还有一点值得注意的是,Kata 的设计初衷强调了能够无缝、便捷的与 OpenStack 和 Kubernetes 集成的能力,这为 OpenStack 、Kubernetes 和 Container 更好的融合铺平了道路。
更详细的内容可以访问:
http://www/katacontainers.io/
https://github.com/hyperhq/runv
Pouch 是什么
相比 Kata,阿里的 Pouch 就没那么新鲜了,只不过是换了个马甲而已。
为什么这么说,因为 Pouch 并不是全新的容器解决方案,而是已经在阿里内部经过千锤百炼的老牌容器技术 t4。2011 年,Linux 内核的 namespace、cgroup 等技术开始成熟,LXC 等容器运行时技术也在同期诞生,阿里作为一家技术公司,在当时便基于 LXC 自研了自己的容器技术 t4,并以产品的形式给内部提供服务。
t4 就是 Pouch 的前身,从时间节点上看,t4 面世比 docker 要早两年,但 t4 有很多问题没有解决,譬如说没有镜像机制。2013 年,docker 横空出世,其带有镜像创新的容器技术,似一阵飓风,所到之处,国内外无不叫好,阿里也不例外,便在现有技术体系结构的基础上融入了 docker 的镜像技术,慢慢打磨,演变成今天的 Pouch。
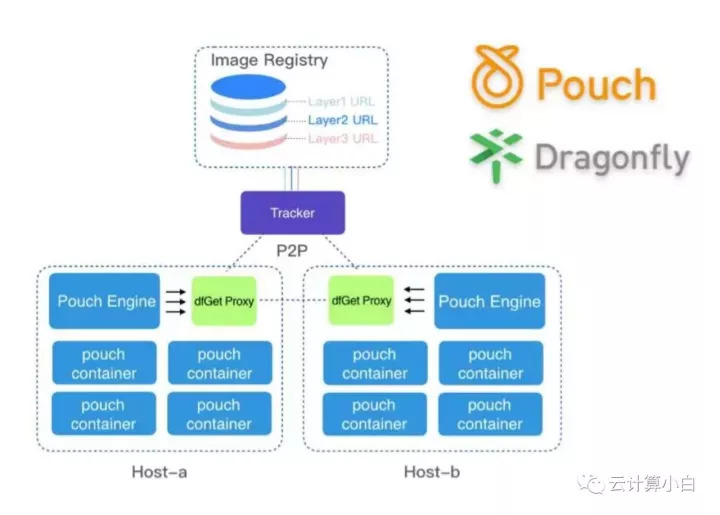
Pouch 针对自身的业务场景对镜像的下载和分发进行了创新。由于阿里的业务体量庞大,集群规模数以万计,这就会存在一个问题就是镜像的下载和分发效率会很低,所以针对此,阿里在 Pouch 中集成了一个镜像分发工具蜻蜓(Dragonfly),蜻蜓基于智能 P2P 技术的文件分发系统,解决了大规模文件分发场景下分发耗时、成功率低、带宽浪费等难题。
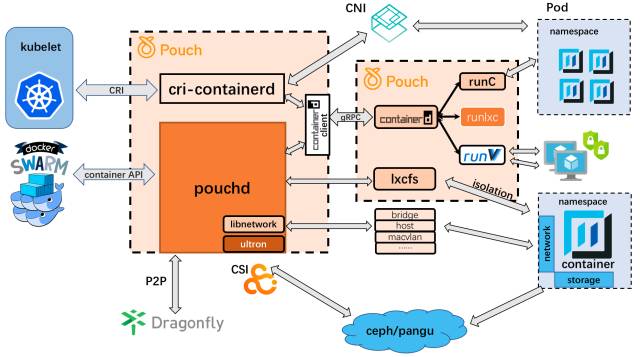
Pouch 的架构主要考虑到两个方面,一方面是如何对接容器编排系统,另一方面是如何加强容器运行时,第一点让 Pouch 有了对外可扩展的能力,譬如可以原生支持 Kubernetes 等编排系统。第二点可以增加 Pouch 对虚拟机和容器的统一管理,让其适应更多的业务场景。
更详细的内容可以访问:
https://github.com/alibaba/pouch
总结
从几种举动中,我们可以看出,未来容器发展具有两大重要方向,分别是容器编排技术和容器的安全加强。这些都是在寻求一种更好的、更有效率的方式来为上层的业务提供更可靠、更安全的支撑。
PS:文章未经我允许,不得转载,否则后果自负。
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。