文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
这是 Linux 性能分析系列的第五篇,前四篇在这里:
一文掌握 Linux 性能分析之 CPU 篇
一文掌握 Linux 性能分析之内存篇
一文掌握 Linux 性能分析之 IO 篇
一文掌握 Linux 性能分析之网络篇
在上篇中,我们已经介绍了几个 Linux 网络方向的性能分析工具,本文再补充几个。总结下来,余下的工具包括但不限于以下几个:
- sar:统计信息历史
- traceroute:测试网络路由
- dtrace:TCP/IP 栈跟踪
- iperf / netperf / netserver:网络性能测试工具
- perf 性能分析神器
由于篇幅有限,本文会先介绍前面两个,其他工具留作后面介绍,大家可以持续关注。
sar
sar 是一个系统历史数据统计工具。统计的信息非常全,包括 CPU、内存、磁盘 I/O、网络、进程、系统调用等等信息,是一个集大成的工具,非常强大。在 Linux 系统上 sar --help 一下,可以看到它的完整用法。
- -A:所有报告的总和
- -u:输出 CPU 使用情况的统计信息
- -v:输出 inode、文件和其他内核表的统计信息
- -d:输出每一个块设备的活动信息
- -r:输出内存和交换空间的统计信息
- -b:显示 I/O和传送速率的统计信息
- -a:文件读写情况
- -c:输出进程统计信息,每秒创建的进程数
- -R:输出内存页面的统计信息
- -y:终端设备活动情况
- -w:输出系统交换活动信息
- -n:输出网络设备统计信息
在平时使用中,我们常常用来分析网络状况,其他几项的通常有更好的工具来分析。所以,本文会重点介绍 sar 在网络方面的分析手法。
Linux 系统用以下几个选项提供网络统计信息:
- -n DEV:网络接口统计信息。
- -n EDEV:网络接口错误。
- -n IP:IP 数据报统计信息。
- -n EIP:IP 错误统计信息。
- -n TCP:TCP 统计信息。
- -n ETCP:TCP 错误统计信息。
- -n SOCK:套接字使用。
我们来看几个示例:
(1)每秒打印 TCP 的统计信息:
sar -n TCP 1
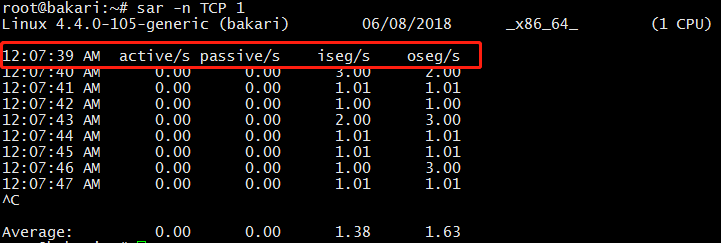
几个参数了解一下:
- active/s:新的 TCP 主动连接(也就是 socket 中的 connect() 事件),单位是:连接数/s。
- passive/s:新的 TCP 被动连接(也就是 socket 中的 listen() 事件)。
- iseg/s:接收的段(传输层以段为传输单位),单位是:段/s
- oseg/s:发送的段。
通过这几个参数,我们基本可以知道当前系统 TCP 连接的负载情况。
(2)每秒打印感兴趣的网卡的统计信息:
sar -n DEV 1 | awk 'NR == 3 || $3 == "eth0"'

几个参数了解一下:
- rxpck/s / txpck/s:网卡接收/发送的数据包,单位是:数据包/s。
- rxkB/s / txkB/s:网卡接收/发送的千字节,单位是:千字节/s。
- rxcmp/s / txcmp/s:网卡每秒接受/发送的压缩数据包,单位是:数据包/s。
- rxmcst/s:每秒接收的多播数据包,单位是:数据包/s。
- %ifutil:网络接口的利用率。
这几个参数对于分析网卡接收和发送的网络吞吐量很有帮助。
(3)错误包和丢包情况分析:
sar -n EDEV 1

几个参数了解一下:
- rxerr/s / txerr/s:每秒钟接收/发送的坏数据包
- coll/s:每秒冲突数
- rxdrop/s:因为缓冲充满,每秒钟丢弃的已接收数据包数
- txdrop/s:因为缓冲充满,每秒钟丢弃的已发送数据包数
- txcarr/s:发送数据包时,每秒载波错误数
- rxfram/s:每秒接收数据包的帧对齐错误数
- rxfifo/s / txfifo/s:接收/发送的数据包每秒 FIFO 过速的错误数
当发现接口传输数据包有问题时,查看以上参数能够让我们快速判断具体是出的什么问题。
OK,这个工具就介绍到这里,以上只是抛砖引玉,更多技巧还需要大家动手去探索,只有动手,才能融会贯通。
traceroute
traceroute 也是一个排查网络问题的好工具,它能显示数据包到达目标主机所经过的路径(路由器或网关的 IP 地址)。如果发现网络不通,我们可以通过这个命令来进一步判断是主机的问题还是网关的问题。
它通过向源主机和目标主机之间的设备发送一系列的探测数据包(UDP 或者 ICMP)来发现设备的存在,实现上利用了递增每一个包的 TTL 时间,来探测最终的目标主机。比如开始 TTL = 1,当到达第一个网关设备的时候,TTL - 1,当 TTL = 0 导致网关响应一个 ICMP 超时报文,这样,如果没有防火墙拦截的话,源主机就知道网关设备的地址。以此类推,逐步增加 TTL 时间,就可以探测到目标主机之间所经过的路径。
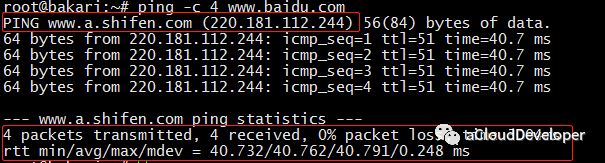
为了防止发送和响应过程出现问题导致丢包,traceroute 默认会发送 3 个探测包,我们可以用 -q x 来改变探测的数量。如果中间设备设置了防火墙限制,会导致源主机收不到响应包,就会显示 * 号。如下是 traceroute baidu 的结果:
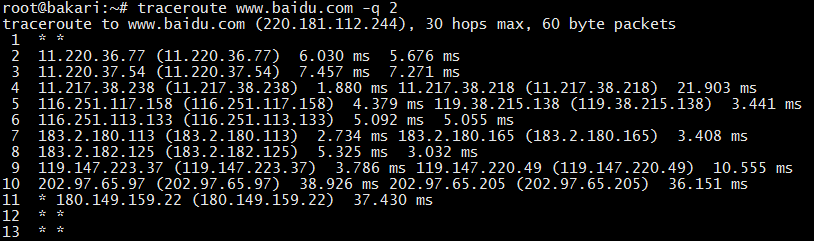
每一行默认会显示设备名称(IP 地址)和对应的响应时间。发送多少个探测包,就显示多少个。如果只想显示 IP 地址可以用 -n 参数,这个参数可以避免 DNS 域名解析,加快响应时间。
和这个工具类似的还有一个工具叫 pathchar,但平时用的不多,我就不介绍了。
以上就是两个工具的简单介绍,工具虽然简单,但只要能解决问题,就是好工具。当然,性能分析不仅仅依靠工具就能解决的,更多需要我们多思考、多动手、多总结,逐步培养自己的系统能力,才能融会贯通。
PS:文章未经我允许,不得转载,否则后果自负。
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。