本文首发于我的公众号 「Linux云计算网络」(id: cloud_dev) ,专注于干货分享,号内有 10T 书籍和视频资源,后台回复「1024」即可免费领取,欢迎大家关注,二维码文末可以扫。
上一篇文章我们详细介绍了 macvlan 这种技术,macvlan 详解,由于它高效易配置的特性,被用在了 Docker 的网络方案设计中,这篇文章就来说说这个。
本文首发于我的公众号 「Linux云计算网络」(id: cloud_dev) ,专注于干货分享,号内有 10T 书籍和视频资源,后台回复「1024」即可免费领取,欢迎大家关注,二维码文末可以扫。
上一篇文章我们详细介绍了 macvlan 这种技术,macvlan 详解,由于它高效易配置的特性,被用在了 Docker 的网络方案设计中,这篇文章就来说说这个。
文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
前面单主机容器网络和多主机容器网络两篇文章,咱们已经从原理上总结了多种容器网络方案,也通过这篇文章探讨了容器网络的背后原理。本文再基于一个宏观的视角,对比几种网络方案,让大家有个完整的认识。
单主机网络就不多说了,因为也比较简单,我们重点对比几种多主机网络方案。
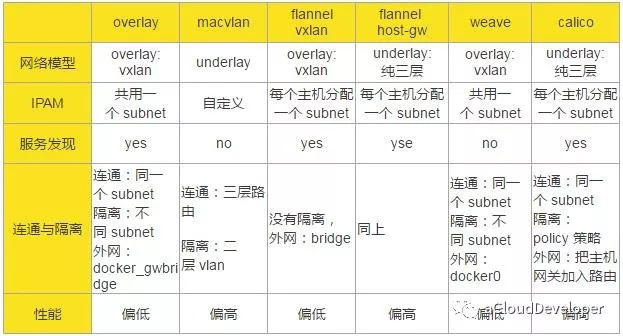
对比的维度有以下几种:网络模型,IP 地址池管理(IP Address Management,IPAM),服务发现,连通与隔离,性能。
网络模型指的是构成跨主机通信的网络结构和实现技术,比如是纯二层转发,还是纯三层转发;是 overlay 网络还是 underlay 网络等等。
IPAM 指的是如何管理容器网络的 IP 池。当容器集群比较大,管理的主机比较多的时候,如何分配各个主机上容器的 IP 是一个比较棘手的问题。Docker 网络有个 subnet 的概念,通常一个主机分配一个 subnet,但也有多个主机共用一个 subnet 的情况,具体的网络方案有不同的考量。具体看下面的表格总结。
服务发现本质上是一个分布式的 key-value 存储系统,用于跨主机通信时保存并同步各主机的网络信息,便于快速建立起各主机之间的网络连接。由于各网络方案实现上各有千秋,并不是所有的跨主机网络方案都要依据服务发现。
连通与隔离指的是容器跨主机之间是否能够互相通信,以及容器与外网(外网不一定指 Internet)之间如何通信。
性能具体指的是通信的时延,我们仅从各个网络方案的原理上来分析得出结论,所以这里的结论并不一定正确,因为不同的部署环境会对性能有一些影响,建议大家还是根据自己的环境动手实验验证为妙。
从原理上说,underlay 网络性能要优于 overlay 网络,因为 overlay 网络存在封包和拆包操作,存在额外的 CPU 和网络开销,所以,几种方案中,macvlan、flannel host-gw、calico 的性能会优于 overlay、flannel vxlan 和 weave。但是这个也不能作为最终生产环境采用的标准,因为 overlay 网络采用 vxlan 作为隧道的话,能支持更多的二层网段,安全性也更高,所以,需要综合考虑。
通过以上分析,我们可以得出以下的结论:
参考:
http://www.cnblogs.com/CloudMan6/p/7587532.html
PS:文章未经我允许,不得转载,否则后果自负。
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。

文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
知其然而不知其所以然,不知也。老古人说得多好,学知识不懂得知识背后的原理,等于白学。
通过前面两篇文章,我们知道了容器的单主机网络和多主机网络,对于这么多网络方案,我们看到对 Docker 的整体网络结构好像没有改动,都是水平扩展的,那 Docker 网络究竟是怎么集成这么多网络方案而不改变自身原有的结构呢?本文就来一探究竟。
要回答这个问题,得从 Docker 的总体框架说起。
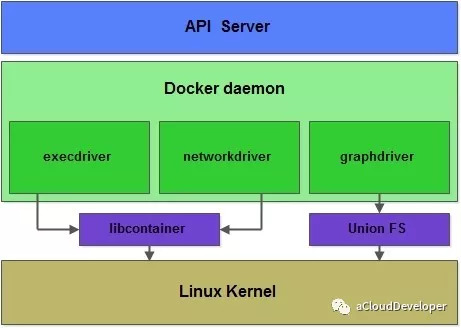
容器和虚拟机一样,都是虚拟化的产品,都包括计算虚拟化,存储虚拟化和 IO 虚拟化。容器作为轻量级的进程,不像虚拟机那般复杂,这三块分别靠三个 Driver 来完成的,execdriver 负责计算虚拟化,networkdriver 负责网络虚拟化,graphdriver 负责存储虚拟化。由此可见,Docker 靠 Driver 这种设计思想来支撑起它的基础平台,再往深了挖,它的每个子模块都随处可见这种设计思想,就网络这个子模块来看,也是如此。
期初的 Docker 网络子模块的代码是分散在 docker daemon 和 libcontainer 中的,libcontainer 是一个独立的容器管理包,execdriver 和 networkdriver 都是通过 libcontainer 来实现对容器的具体操作。
随着业务场景越来越复杂,这种内嵌的方式很难针对不同的网络场景进行扩展。后来,Docker 收购了一个做多主机网络解决方案的公司 SocketPlane,然后让那帮人专门来解决这个问题。这就是接下来要介绍的 libnetwork。
libnetwork 起初的做法很简单,就是将 docker engine 和 libcontainer 中网络相关的代码抽出来,合并成一个单独的库,做成网络抽象层,并对外提供 API。Docker 的愿景就是希望 libnetwork 能够做像 libcontainer 那样,成为一个多平台的容器网络基础包。
后来受一个 GitHub issue ( https://github.com/moby/moby/issues/9983) 的启发,libnetwork 引入容器网络模型(Container Network Model,CNM),该模型进一步对 Docker 的网络结构进行了细分,提出了三个概念:network、sandbox 和 endpoint。
network 是一个抽象的概念,你可以把它理解成一个网络的插件,或者是网络的 Driver,比如说单主机网络的 Driver 就有 none、host、bridge,joined container 这四种,多主机网络就有 overlay、macvlan、flannel 这些。network 可以独立出去做,只需调用 Docker 对外提供的 API 就可以作为插件集成到 Docker 网络中使用。
sandbox 实现了容器内部的网络栈,它定义容器的虚拟网卡,路由表和 DNS 等配置,其实就是一个标准的 linux network namespace 实现。
network 实现了一个第三方的网络栈,sandbox 则实现了容器内部的网络栈,那这两者怎么联系起来呢?答案就是通过 endpoint,endpoint 实现了 veth pair,一个 endpoint 就表示一对 veth pair,一端挂在容器中,另一端挂在 network 中。
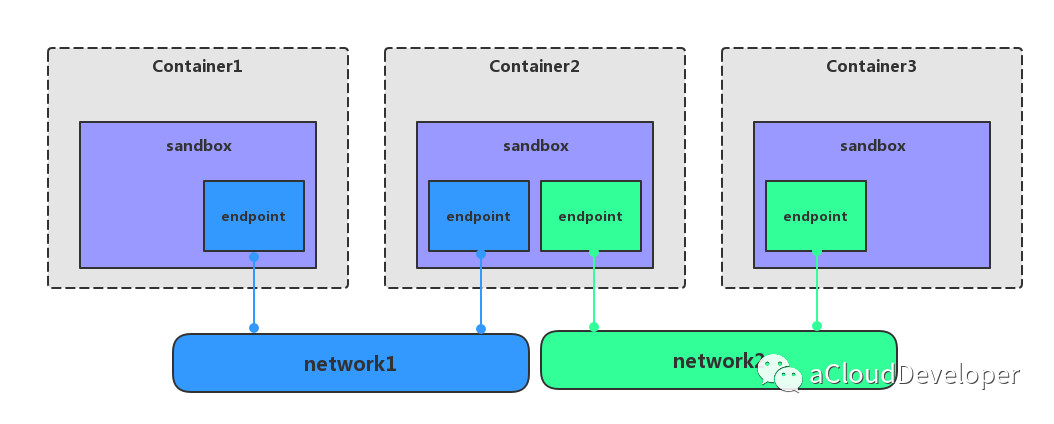
network、sandbox 和 endpoint 三者之间的关系:
一个 network 可以包含多个 endpoint,自然也就包含多个 sandbox。
一个 sandbox 可以包含多个 endpoint,可以属于多个 network。
一个 endpoint 只可以属于一个 network,并且只属于一个 sandbox。
如上图显示三个容器,每个容器一个 sandbox,除了第二个容器有两个 endpoint 分别接入 network1 和 network2 之外,其余 sandbox 都只有一个 endpoint 分别接入不同的 network。
到此,我们就可以解答文章开篇提到的问题,“不同的网络方案如何集成到 Docker 网络模型中而不改变原有结构?”
答案就是基于 libnetwork CNM,将各个网络模型以插件或 Driver 的形式集成到 Docker 网络中来,与 docker daemon 协同工作,实现容器网络。Docker 原生的 Driver 包括单主机的 none、bridge、joined container 和 多主机的 overlay、macvlan,第三方 Driver 就包括多主机的 flannel、weave、calico 等。
PS:文章未经我允许,不得转载,否则后果自负。
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。
文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
上篇文章介绍了容器网络的单主机网络,本文将进一步介绍多主机网络,也就是跨主机的网络。总结下来,多主机网络解决方案包括但不限于以下几种:overlay、macvlan、flannel、weave、cacico 等,下面将分别一一介绍这几种网络,
PS:本文仅从原理上对几种网络进行简单的对比总结,不涉及太多的细节。
俗称隧道网络,它是基于 VxLAN 协议来将二层数据包封装到 UDP 中进行传输的,目的是扩展二层网段,因为 VLAN 使用 12bit 标记 VLAN ID,最多支持 4094 个 VLAN,这对于大型云网络会成为瓶颈,而 VxLAN ID 使用 24bit 来标记,支持多达 16777216 个二层网段,所以 VxLAN 是扩展了 VLAN,也叫做大二层网络。
overlay 网络需要一个全局的“上帝”来记录它网络中的信息,比如主机地址,子网等,这个上帝在 Docker 中是由服务发现协议来完成的,服务发现本质上是一个 key-value 数据库,要使用它,首先需要向它告知(注册)一些必要的信息(如网络中需要通信的主机),然后它就会自动去收集、同步网络的信息,同时,还会维护一个 IP 地址池,分配给主机中的容器使用。Docker 中比较有名的服务发现有 Consul、Etcd 和 ZooKeeper。overlay 网络常用 Consul。
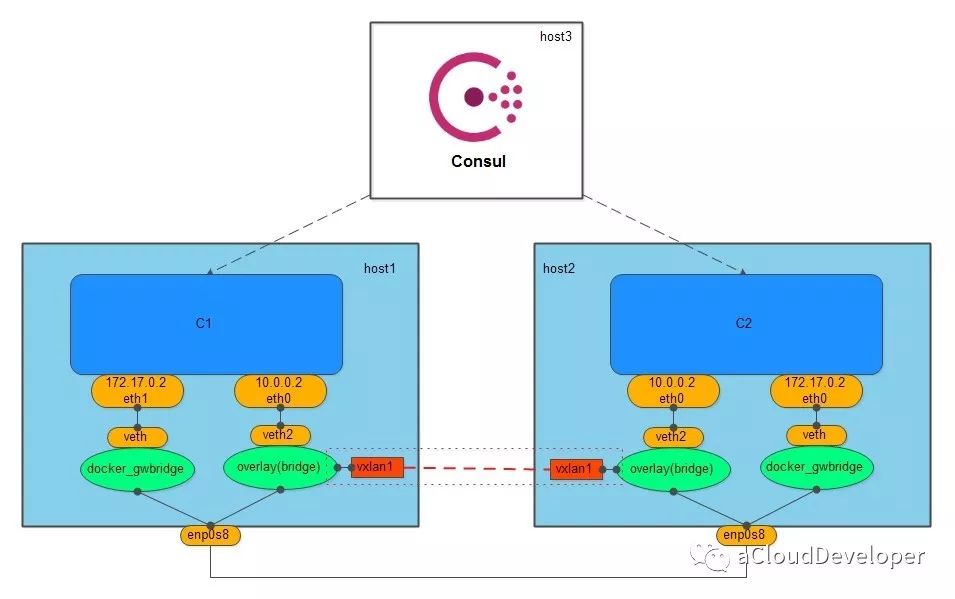
创建 overlay 网络会创建一个 Linux bridge br0,br0 会创建两个接口,一个 veth2 作为与容器的虚拟网卡相连的 veth pair,另一个 vxlan1 负责与其他 host 建立 VxLAN 隧道,跨主机的容器就通过这个隧道来进行通信。
为了保证 overlay 网络中的容器与外网互通,Docker 会创建另一个 Linux bridge docker_gwbridge,同样,该 bridge 也存在一对 veth pair,要与外围通信的容器可以通过这对 veth pair 到达 docker_gwbridge,进而通过主机 NAT 访问外网。
macvlan 就如它的名字一样,是一种网卡虚拟化技术,它能够将一个物理网卡虚拟出多个接口,每个接口都可以配置 MAC 地址,同样每个接口也可以配自己的 IP,每个接口就像交换机的端口一样,可以为它划分 VLAN。
macvlan 的做法其实就是将这些虚拟出来的接口与 Docker 容器直连来达到通信的目的。一个 macvlan 网络对应一个接口,不同的 macvlan 网络分配不同的子网,因此,相同的 macvlan 之间可以互相通信,不同的 macvlan 网络之间在二层上不能通信,需要借助三层的路由器才能完成通信,如下,显示的就是两个不同的 macvlan 网络之间的通信流程。
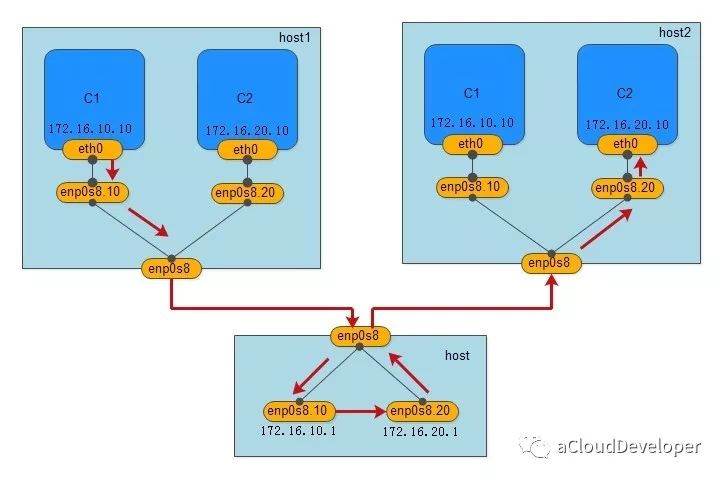
我们用一个 Linux 主机,通过配置其路由表和 iptables,将其配成一个路由器(当然是虚拟的),就可以完成不同 macvlan 网络之间的数据交换,当然用物理路由器也是没毛病的。
flannel 网络也需要借助一个全局的上帝来同步网络信息,一般使用的是 etcd。
flannel 网络不会创建新的 bridge,而是用默认的 docker0,但创建 flannel 网络会在主机上创建一个虚拟网卡,挂在 docker0 上,用于跨主机通信。
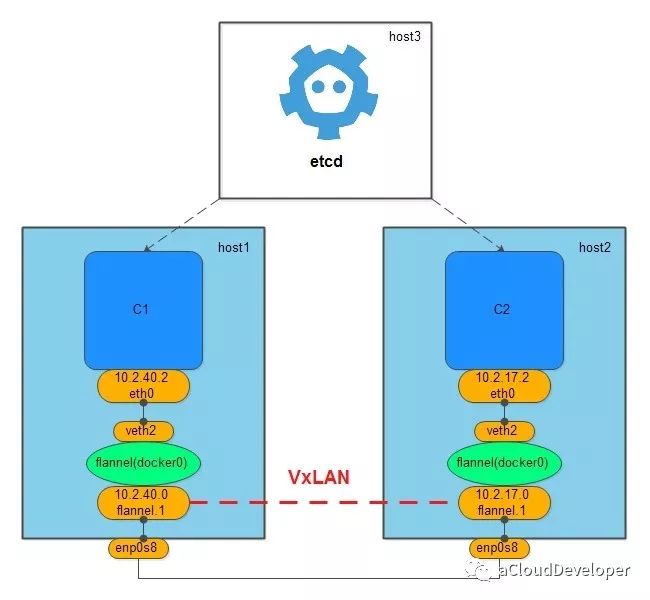
组件方式让 flannel 多了几分灵活性,它可以使用二层的 VxLAN 隧道来封装数据包完成跨主机通信,也可以使用纯三层的方案来通信,比如 host-gw,只需修改一个配置文件就可以完成转化。
weave 网络没有借助服务发现协议,也没有 macvlan 那样的虚拟化技术,只需要在不同主机上启动 weave 组件就可以完成通信。
创建 weave 网络会创建两个网桥,一个是 Linux bridge weave,一个是 datapath,也就是 OVS,weave 负责将容器加入 weave 网络中,OVS 负责将跨主机通信的数据包封装成 VxLAN 包进行隧道传输。
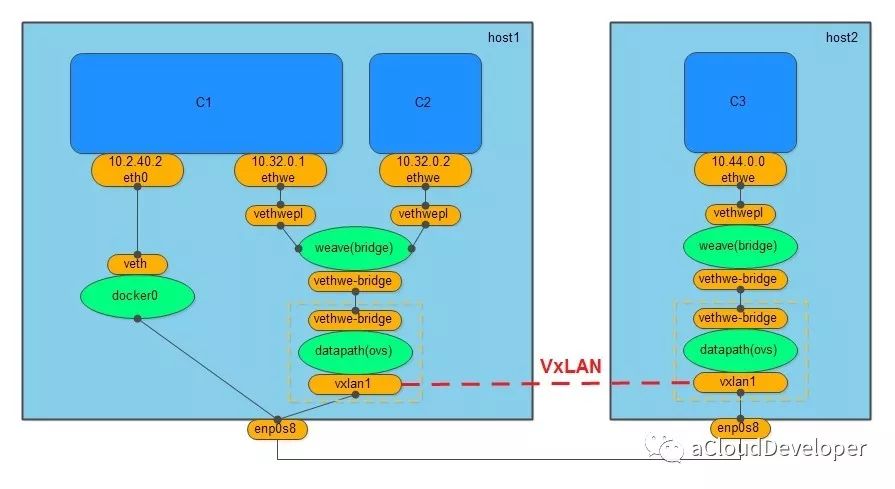
同样,weave 网络也不支持与外网通信,Docker 提供 docker0 来满足这个需求。
weave 网络通过组件化的方式使得网络分层比较清晰,两个网桥的分工也比较明确,一个用于跨主机通信,相当于一个路由器,一个负责将本地网络加入 weave 网络。
calico 是一个纯三层的网络,它没有创建任何的网桥,它之所以能完成跨主机的通信,是因为它记住 etcd 将网络中各网段的路由信息写进了主机中,然后创建的一对的 veth pair,一块留在容器的 network namespace 中,一块成了主机中的虚拟网卡,加入到主机路由表中,从而打通不同主机中的容器通信。
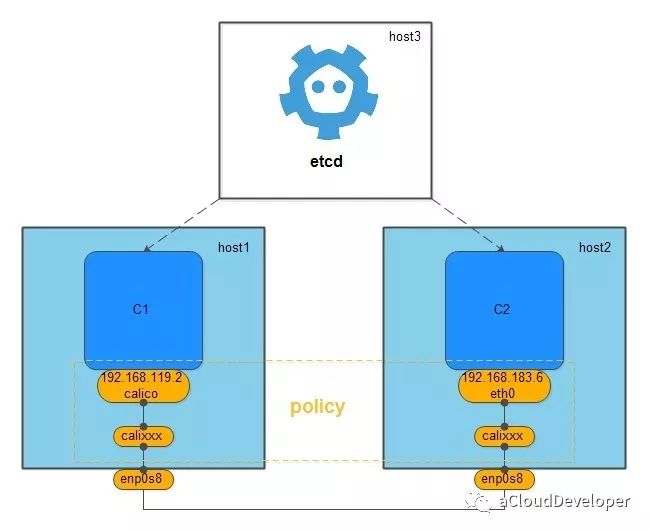
calico 相较其他几个网络方案最大优点是它提供 policy 机制,用户可以根据自己的需求自定义 policy,一个 policy 可能对应一条 ACL,用于控制进出容器的数据包,比如我们建立了多个 calico 网络,想控制其中几个网络可以互通,其余不能互通,就可以修改 policy 的配置文件来满足要求,这种方式大大增加了网络连通和隔离的灵活性。
1、除了以上的几种方案,跨主机容器网络方案还有很多,比如:Romana,Contiv 等,本文就不作过多展开了,大家感兴趣可以查阅相关资料了解。
2、跨主机的容器网络通常要为不同主机的容器维护一个 IP 池,所以大多方案需要借助第三方的服务发现方案。
3、跨主机容器网络按传输方式可以分为纯二层网络,隧道网络(大二层网络),以及纯三层网络。
PS:文章未经我允许,不得转载,否则后果自负。
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。
文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
当容器逐步向容器集群,容器云技术演进的时候,一个不得不面对的问题就是各个容器的管理问题,有些容器需要交互,有些容器需要隔离,如何保证这些操作能够顺利地进行,这个时候,很多容器管理和编排的平台就应运而生了。首先,当然是 Docker 社区自己开发的 Swarm+Machine+Compose 的集群管理套件,然后还有 Twitter 主推 Apache 的 Mesos,最有名的应该为 Google 开源的 Kubernetes。
这些平台综合了容器集群资源管理,服务发现和扩容缩融等问题,是一个集大成的解决方案,但其实这些问题本质上都离不开网络,资源在各容器之间调度需要网络,服务发现需要网络,所以,可以说网络是容器集群环境下最基础的一环。
Docker 容器网络根据容器的部署位置,可以分为单主机网络(host)和多主机网络(multi-host),本文先看 Docker host 网络。
Docker host 网络分为 none,host,joined container 和 bridge 网络。
none 网络模式下,Docker 容器拥有自己的 network namespace,但是并不为容器进行任何的网络配置,也就是说容器除了 network namespace 本身自带的 localback 网卡外什么都没有,包括网卡、IP、路由等信息。用户如何要使用 none 网络,就需要自己添加特定的网卡,并配置 IP、路由等信息,但一般不会这么干,none 网络很好地做到了隔离,一般是用来跑那些对安全性要求极高且不需要联网的应用。
比如某个容器的唯一用途是生成随机密码,就可以放到 none 网络中避免密码被窃取。
想要使 Docker 使用 none 网络,只需要在创建容器的时候附带 –network = none 即可。
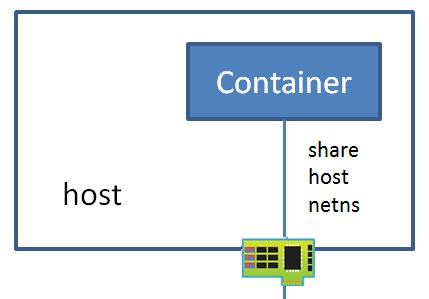
host 网络,顾名思义就是 Docker 容器使用宿主机的网络,相当于和 host 共用了同一个 network namespace,Docker 容器使用 host 的网卡、IP 和路由等功能对外通信。
虽然这种模式下 Docker 没有创建独立的 network namespace,但其他 namespace 仍然是隔离的,如文件系统、进程列表等。host 网络最大的好处就是使得 Docker 容器对外通信变得简单,直接使用 host 的 IP 进行通信即可,但缺点也很明显,就是降低了隔离性,同时还会存在和其他容器对网络资源的竞争与冲突的问题。
同样要使用 host 网络,只需创建容器时附带 –network = host 即可。
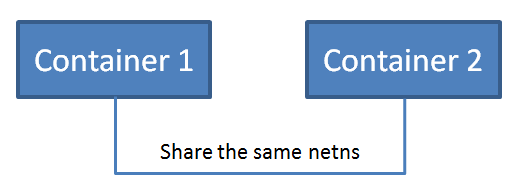
joined container 网络和 host 网络不同的是,它是和其他的 container 共享一个 network namespace,一个 network namespace 可以被一个或者多个 Docker 容器共享。在这种模式下,两个容器之间可以通过 localback 回环网卡通信,增加了容器间通信的便利性。
同样可以在创建容器时,使用参数 –network = container:another_container_name 来和另外容器共享网络。
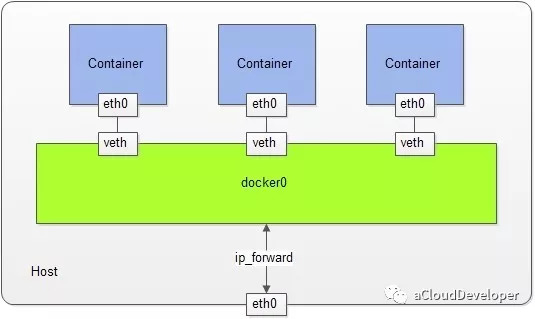
bridge 网络是最常用的网络模式,它兼顾了安全性和功能的完备性,但其与外部通信要通过 NAT 转换,在复杂的网络场景下会存在诸多不便。
bridge 网络在创建的时候通过 –network = bridge 指定,Docker daemon 会为创建的容器自动创建一个 Docker 网桥——docker0(也可以人为指定名称 –driver bridge my_net),这个 docker0 就用来联结 Docker 容器和 host 的桥梁。
然后,Docker daemon 会创建一对虚拟网卡 veth pair,一块网卡留在宿主机的 root network namespace 中,并绑定到 docker0 上,另一块放在新创建的 network namespace 中,命名为 eth0,并为其配置 IP 和路由,将其网关设为 docker0,如下,这样整个容器的 bridge 网络通信环境就建立起来了,其他容器的建立方式也是如此,最终各容器之间就通过 docker0 这个桥梁互联互通了。
下文将讨论更为复杂的 multi-host 网络。
PS:文章未经我允许,不得转载,否则后果自负。
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。
文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
前面两篇文章我们总结了 Docker 背后使用的资源隔离技术 Linux namespace,本篇将讨论另外一个技术——资源限额,这是由 Linux cgroups 来实现的。
cgroups 是 Linux 内核提供的一种机制,这种机制可以根据需求把一系列任务及子任务整合(或分隔)到按资源划分等级的不同组内,从而为系统资源管理提供一个统一的框架。(来自 《Docker 容器与容器云》)
通俗来说,cgroups 可以限制和记录任务组(进程组或线程组)使用的物理资源(包括 CPU、内存、IO 等)。
为了方便用户(程序员)操作,cgroups 以一个伪文件系统的方式实现,并对外提供 API,用户对文件系统的操作就是对 cgroups 的操作。
从实现上来,cgroups 实际上是给每个执行任务挂了一个钩子,当任务执行过程中涉及到对资源的分配使用时,就会触发钩子上的函数对相应的资源进行检测,从而对资源进行限制和优先级分配。
总结下来,cgroups 提供以下四个功能:
资源限制: cgroups 可以对任务使用的资源总额进行限制,如设定应用运行时使用内存的上限,一旦超过这个配额就发出 OOM(Out of Memory)提示。
优先级分配: 通过分配的 CPU 时间片数量和磁盘 IO 带宽大小,实际上就相当于控制了任务运行的优先级。
资源统计: cgroups 可以统计系统的资源使用,如 CPU 使用时长、内存用量等,这个功能非常适用于计费。
任务控制: cgroups 可以对任务执行挂起、恢复等操作。
cgroups 在设计时根据不同的资源类别分为不同的子系统,一个子系统本质上是一个资源控制器,比如 CPU 资源对应 CPU 子系统,负责控制 CPU 时间片的分配,内存对应内存子系统,负责限制内存的使用量。进一步,一个子系统或多个子系统可以组成一个 cgroup,cgroups 中的资源控制都是以 cgroup 为单位来实现,一个任务(或进程或线程)可以加入某个 cgroup,也可以从一个 cgroup 移动到另一个 cgroup,但这里有一些限制,在此就不再赘述了,详细查阅相关资料了解。
对于我们来说,最关键的是知道怎么用,下面就针对 CPU、内存和 IO 资源来看 Docker 是如何使用的?
对于 CPU,Docker 使用参数 -c 或 –cpu-shares 来设置一个容器使用的 CPU 权重,权重的大小也影响了 CPU 使用的优先级。
如下,启动两个容器,并分配不同的 CPU 权重,最终 CPU 使用率情况:1
2docker run --name "container_A" -c 1024 ubuntu
docker run --name "container_B" -c 512 ubuntu

当只有一个容器时,即使指定较少的 CPU 权重,它也会占满整个 CPU,说明这个权重只是相对权重,如下将上面的 “container_A” 停止,“container_B” 就分配到全部可用的 CPU。

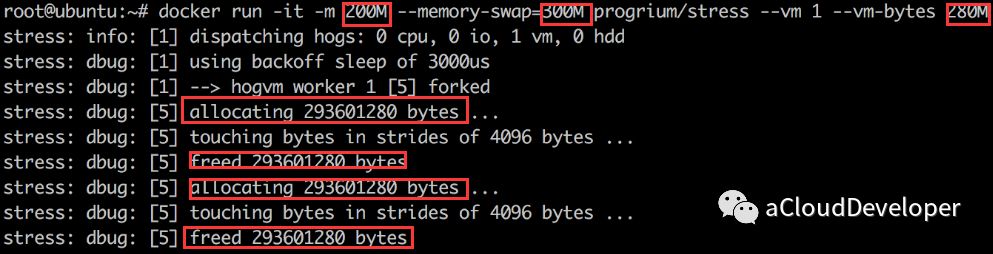
对于内存,Docker 使用 -m(设置内存的限额)和 –memory-swap(设置内存和 swap 的限额)来控制容器内存的使用量,如下,给容器限制 200M 的内存和 100M 的 swap,然后给容器内的一个工作线程分配 280M 的内存,因为 280M 在容许的 300M 范围内,没有问题。其内存分配过程是不断分配又释放,如下:
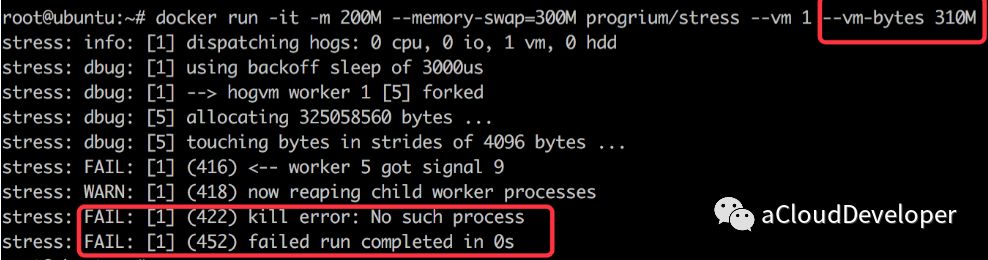
如果让工作线程使用内存超过 300M,则出现内存超限的错误,容器退出,如下:
对于 IO 资源,其使用方式与 CPU 一样,使用 –blkio-weight 来设置其使用权重,IO 衡量的两个指标是 bps(byte per second,每秒读写的数据量) 和 iops(io per second, 每秒 IO 的次数),实际使用,一般使用这两个指标来衡量 IO 读写的带宽,几种使用参数如下:
假如限制容器对其文件系统 /dev/sda 的 bps 写速率为 30MB/s,则在容器中用 dd 测试其写磁盘的速率如下,可见小于 30MB/s。

如果是正常情况下,我的机器可以达到 56.7MB/s,一般都是超 1G 的。

上面几个资源使用限制的例子,本质上都是调用了 Linux kernel 的 cgroups 机制来实现的,每个容器创建后,Linux 会为每个容器创建一个 cgroup 目录,以容器的 ID 命名,目录在 /sys/fs/cgroup/ 中,针对上面的 CPU 资源限制的例子,我们可以在 /sys/fs/cgroup/cpu/docker 中看到相关信息,如下:

其中,cpu.shares 中保存的就是限制的数值,其他还有很多项,感兴趣可以动手实验看看。
cgroups 的作用,cgroups 的实现,cgroups 的子系统机制,CPU、内存和 IO 的使用方式,以及对应 Linux 的 cgroups 文件目录。
PS:文章未经我允许,不得转载,否则后果自负。
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。
文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
上篇我们从进程 clone 的角度,结合代码简单分析了 Linux 提供的 6 种 namespace,本篇从源码上进一步分析 Linux namespace,让你对 Docker namespace 的隔离机制有更深的认识。我用的是 Linux-4.1.19 的版本,由于 namespace 模块更新都比较少,所以,只要 3.0 以上的版本都是差不多的。
由于 Linux namespace 是用来做进程资源隔离的,所以在进程描述符中,一定有 namespace 所对应的信息,我们可以从这里开始切入代码。
首先找到描述进程信息 task_struct,找到指向 namespace 的结构 struct *nsproxy(sched.h):1
2
3
4
5
6struct task_struct {
......
/* namespaces */
struct nsproxy *nsproxy;
......
}
其中 nsproxy 结构体定义在 nsproxy.h 中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21/*
* A structure to contain pointers to all per-process
* namespaces - fs (mount), uts, network, sysvipc, etc.
*
* 'count' is the number of tasks holding a reference.
* The count for each namespace, then, will be the number
* of nsproxies pointing to it, not the number of tasks.
*
* The nsproxy is shared by tasks which share all namespaces.
* As soon as a single namespace is cloned or unshared, the
* nsproxy is copied.
*/
struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns;
struct net *net_ns;
};
extern struct nsproxy init_nsproxy;
这个结构是被所有 namespace 所共享的,只要一个 namespace 被 clone 了,nsproxy 也会被 clone。注意到,由于 user namespace 是和其他 namespace 耦合在一起的,所以没出现在上述结构中。
同时,nsproxy.h 中还定义了一些对 namespace 的操作,包括 copy_namespaces 等。1
2
3
4
5
6int copy_namespaces(unsigned long flags, struct task_struct *tsk);
void exit_task_namespaces(struct task_struct *tsk);
void switch_task_namespaces(struct task_struct *tsk, struct nsproxy *new);
void free_nsproxy(struct nsproxy *ns);
int unshare_nsproxy_namespaces(unsigned long, struct nsproxy **,
struct fs_struct *);
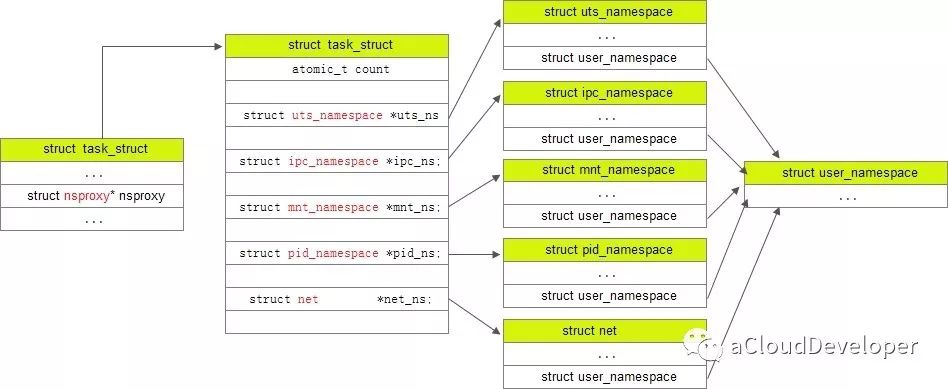
task_struct,nsproxy,几种 namespace 之间的关系如下所示:
在各个 namespace 结构定义下都有个 init 函数,nsproxy 也有个 init_nsproxy 函数,init_nsproxy 在 task 初始化的时候会被初始化,附带的,init_nsproxy 中定义了各个 namespace 的 init 函数,如下:
在 init_task 函数中(init_task.h):1
2
3
4
5
6
7
8
9
10/*
* INIT_TASK is used to set up the first task table, touch at
* your own risk!. Base=0, limit=0x1fffff (=2MB)
*/
#define INIT_TASK(tsk) \
{
......
.nsproxy = &init_nsproxy,
......
}
继续跟进 init_nsproxy,在 nsproxy.c 中:1
2
3
4
5
6
7
8
9
10
11
12struct nsproxy init_nsproxy = {
.count = ATOMIC_INIT(1),
.uts_ns = &init_uts_ns,
#if defined(CONFIG_POSIX_MQUEUE) || defined(CONFIG_SYSVIPC)
.ipc_ns = &init_ipc_ns,
#endif
.mnt_ns = NULL,
.pid_ns_for_children = &init_pid_ns,
#ifdef CONFIG_NET
.net_ns = &init_net,
#endif
};
可见,init_nsproxy 中,对 uts, ipc, pid, net 都进行了初始化,但 mount 却没有。
初始化完之后,下面看看如何创建一个新的 namespace,通过前面的文章,我们知道是通过 clone 函数来完成的,在 Linux kernel 中,fork/vfork() 对 clone 进行了封装,如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46#ifdef __ARCH_WANT_SYS_FORK
SYSCALL_DEFINE0(fork)
{
#ifdef CONFIG_MMU
return do_fork(SIGCHLD, 0, 0, NULL, NULL);
#else
/* can not support in nommu mode */
return -EINVAL;
#endif
}
#endif
#ifdef __ARCH_WANT_SYS_VFORK
SYSCALL_DEFINE0(vfork)
{
return do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, 0, 0, NULL, NULL);
}
#endif
#ifdef __ARCH_WANT_SYS_CLONE
#ifdef CONFIG_CLONE_BACKWARDS
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
int __user *, parent_tidptr,
int, tls_val,
int __user *, child_tidptr)
#elif defined(CONFIG_CLONE_BACKWARDS2)
SYSCALL_DEFINE5(clone, unsigned long, newsp, unsigned long, clone_flags,
int __user *, parent_tidptr,
int __user *, child_tidptr,
int, tls_val)
#elif defined(CONFIG_CLONE_BACKWARDS3)
SYSCALL_DEFINE6(clone, unsigned long, clone_flags, unsigned long, newsp,
int, stack_size,
int __user *, parent_tidptr,
int __user *, child_tidptr,
int, tls_val)
#else
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
int __user *, parent_tidptr,
int __user *, child_tidptr,
int, tls_val)
#endif
{
return do_fork(clone_flags, newsp, 0, parent_tidptr, child_tidptr);
}
#endif
可以看到,无论是 fork() 还是 vfork(),最终都会调用到 do_fork() 函数:
1 | /* |
do_fork() 首先调用 copy_process 将父进程信息复制给子进程,然后调用 vfork() 完成相关的初始化工作,接着调用 wake_up_new_task() 将进程加入调度器中,为之分配 CPU。最后,等待子进程退出。
copy_process():1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
int retval;
// 创建进程描述符指针
struct task_struct *p;
// 检查 clone flags 的合法性,比如 CLONE_NEWNS 与 CLONE_FS 是互斥的
if ((clone_flags & (CLONE_NEWNS|CLONE_FS)) == (CLONE_NEWNS|CLONE_FS))
return ERR_PTR(-EINVAL);
if ((clone_flags & (CLONE_NEWUSER|CLONE_FS)) == (CLONE_NEWUSER|CLONE_FS))
return ERR_PTR(-EINVAL);
/*
* Thread groups must share signals as well, and detached threads
* can only be started up within the thread group.
*/
if ((clone_flags & CLONE_THREAD) && !(clone_flags & CLONE_SIGHAND))
return ERR_PTR(-EINVAL);
/*
* Shared signal handlers imply shared VM. By way of the above,
* thread groups also imply shared VM. Blocking this case allows
* for various simplifications in other code.
*/
if ((clone_flags & CLONE_SIGHAND) && !(clone_flags & CLONE_VM))
return ERR_PTR(-EINVAL);
/*
* Siblings of global init remain as zombies on exit since they are
* not reaped by their parent (swapper). To solve this and to avoid
* multi-rooted process trees, prevent global and container-inits
* from creating siblings.
*/
// 比如CLONE_PARENT时得检查当前signal flags是否为SIGNAL_UNKILLABLE,防止kill init进程。
if ((clone_flags & CLONE_PARENT) &&
current->signal->flags & SIGNAL_UNKILLABLE)
return ERR_PTR(-EINVAL);
/*
* If the new process will be in a different pid or user namespace
* do not allow it to share a thread group or signal handlers or
* parent with the forking task.
*/
if (clone_flags & CLONE_SIGHAND) {
if ((clone_flags & (CLONE_NEWUSER | CLONE_NEWPID)) ||
(task_active_pid_ns(current) !=
current->nsproxy->pid_ns_for_children))
return ERR_PTR(-EINVAL);
}
retval = security_task_create(clone_flags);
if (retval)
goto fork_out;
retval = -ENOMEM;
// 复制当前的 task_struct
p = dup_task_struct(current);
if (!p)
goto fork_out;
ftrace_graph_init_task(p);
rt_mutex_init_task(p);
#ifdef CONFIG_PROVE_LOCKING
DEBUG_LOCKS_WARN_ON(!p->hardirqs_enabled);
DEBUG_LOCKS_WARN_ON(!p->softirqs_enabled);
#endif
retval = -EAGAIN;
// 检查进程是否超过限制,由 OS 定义
if (atomic_read(&p->real_cred->user->processes) >=
task_rlimit(p, RLIMIT_NPROC)) {
if (p->real_cred->user != INIT_USER &&
!capable(CAP_SYS_RESOURCE) && !capable(CAP_SYS_ADMIN))
goto bad_fork_free;
}
current->flags &= ~PF_NPROC_EXCEEDED;
retval = copy_creds(p, clone_flags);
if (retval < 0)
goto bad_fork_free;
/*
* If multiple threads are within copy_process(), then this check
* triggers too late. This doesn't hurt, the check is only there
* to stop root fork bombs.
*/
retval = -EAGAIN;
// 检查进程数是否超过 max_threads,由内存大小定义
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
// ......
// 初始化 io 计数器
task_io_accounting_init(&p->ioac);
acct_clear_integrals(p);
// 初始化 CPU 定时器
posix_cpu_timers_init(p);
// ......
// 初始化进程数据结构,并为进程分配 CPU,进程状态设置为 TASK_RUNNING
/* Perform scheduler related setup. Assign this task to a CPU. */
retval = sched_fork(clone_flags, p);
if (retval)
goto bad_fork_cleanup_policy;
retval = perf_event_init_task(p);
if (retval)
goto bad_fork_cleanup_policy;
retval = audit_alloc(p);
if (retval)
goto bad_fork_cleanup_perf;
/* copy all the process information */
// 复制所有进程信息,包括文件系统,信号处理函数、信号、内存管理等
shm_init_task(p);
retval = copy_semundo(clone_flags, p);
if (retval)
goto bad_fork_cleanup_audit;
retval = copy_files(clone_flags, p);
if (retval)
goto bad_fork_cleanup_semundo;
retval = copy_fs(clone_flags, p);
if (retval)
goto bad_fork_cleanup_files;
retval = copy_sighand(clone_flags, p);
if (retval)
goto bad_fork_cleanup_fs;
retval = copy_signal(clone_flags, p);
if (retval)
goto bad_fork_cleanup_sighand;
retval = copy_mm(clone_flags, p);
if (retval)
goto bad_fork_cleanup_signal;
// !!! 复制 namespace
retval = copy_namespaces(clone_flags, p);
if (retval)
goto bad_fork_cleanup_mm;
retval = copy_io(clone_flags, p);
if (retval)
goto bad_fork_cleanup_namespaces;
// 初始化子进程内核栈
retval = copy_thread(clone_flags, stack_start, stack_size, p);
if (retval)
goto bad_fork_cleanup_io;
// 为新进程分配新的 pid
if (pid != &init_struct_pid) {
pid = alloc_pid(p->nsproxy->pid_ns_for_children);
if (IS_ERR(pid)) {
retval = PTR_ERR(pid);
goto bad_fork_cleanup_io;
}
}
// ......
// 返回新进程 p
return p;
}
copy_process 主要分为三步:首先调用 dup_task_struct() 复制当前的进程描述符信息 task_struct,为新进程分配新的堆栈,第二步调用 sched_fork() 初始化进程数据结构,为其分配 CPU,把进程状态设置为 TASK_RUNNING,最后一步就是调用 copy_namespaces() 复制 namesapces。我们重点关注最后一步 copy_namespaces():1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37/*
* called from clone. This now handles copy for nsproxy and all
* namespaces therein.
*/
int copy_namespaces(unsigned long flags, struct task_struct *tsk)
{
struct nsproxy *old_ns = tsk->nsproxy;
struct user_namespace *user_ns = task_cred_xxx(tsk, user_ns);
struct nsproxy *new_ns;
if (likely(!(flags & (CLONE_NEWNS | CLONE_NEWUTS | CLONE_NEWIPC |
CLONE_NEWPID | CLONE_NEWNET)))) {
get_nsproxy(old_ns);
return 0;
}
if (!ns_capable(user_ns, CAP_SYS_ADMIN))
return -EPERM;
/*
* CLONE_NEWIPC must detach from the undolist: after switching
* to a new ipc namespace, the semaphore arrays from the old
* namespace are unreachable. In clone parlance, CLONE_SYSVSEM
* means share undolist with parent, so we must forbid using
* it along with CLONE_NEWIPC.
*/
if ((flags & (CLONE_NEWIPC | CLONE_SYSVSEM)) ==
(CLONE_NEWIPC | CLONE_SYSVSEM))
return -EINVAL;
new_ns = create_new_namespaces(flags, tsk, user_ns, tsk->fs);
if (IS_ERR(new_ns))
return PTR_ERR(new_ns);
tsk->nsproxy = new_ns;
return 0;
}
可见,copy_namespace() 主要基于“旧的” namespace 创建“新的” namespace,核心函数在于 create_new_namespaces:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67/*
* Create new nsproxy and all of its the associated namespaces.
* Return the newly created nsproxy. Do not attach this to the task,
* leave it to the caller to do proper locking and attach it to task.
*/
static struct nsproxy *create_new_namespaces(unsigned long flags,
struct task_struct *tsk, struct user_namespace *user_ns,
struct fs_struct *new_fs)
{
struct nsproxy *new_nsp;
int err;
// 创建新的 nsproxy
new_nsp = create_nsproxy();
if (!new_nsp)
return ERR_PTR(-ENOMEM);
//创建 mnt namespace
new_nsp->mnt_ns = copy_mnt_ns(flags, tsk->nsproxy->mnt_ns, user_ns, new_fs);
if (IS_ERR(new_nsp->mnt_ns)) {
err = PTR_ERR(new_nsp->mnt_ns);
goto out_ns;
}
//创建 uts namespace
new_nsp->uts_ns = copy_utsname(flags, user_ns, tsk->nsproxy->uts_ns);
if (IS_ERR(new_nsp->uts_ns)) {
err = PTR_ERR(new_nsp->uts_ns);
goto out_uts;
}
//创建 ipc namespace
new_nsp->ipc_ns = copy_ipcs(flags, user_ns, tsk->nsproxy->ipc_ns);
if (IS_ERR(new_nsp->ipc_ns)) {
err = PTR_ERR(new_nsp->ipc_ns);
goto out_ipc;
}
//创建 pid namespace
new_nsp->pid_ns_for_children =
copy_pid_ns(flags, user_ns, tsk->nsproxy->pid_ns_for_children);
if (IS_ERR(new_nsp->pid_ns_for_children)) {
err = PTR_ERR(new_nsp->pid_ns_for_children);
goto out_pid;
}
//创建 network namespace
new_nsp->net_ns = copy_net_ns(flags, user_ns, tsk->nsproxy->net_ns);
if (IS_ERR(new_nsp->net_ns)) {
err = PTR_ERR(new_nsp->net_ns);
goto out_net;
}
return new_nsp;
// 出错处理
out_net:
if (new_nsp->pid_ns_for_children)
put_pid_ns(new_nsp->pid_ns_for_children);
out_pid:
if (new_nsp->ipc_ns)
put_ipc_ns(new_nsp->ipc_ns);
out_ipc:
if (new_nsp->uts_ns)
put_uts_ns(new_nsp->uts_ns);
out_uts:
if (new_nsp->mnt_ns)
put_mnt_ns(new_nsp->mnt_ns);
out_ns:
kmem_cache_free(nsproxy_cachep, new_nsp);
return ERR_PTR(err);
}
在create_new_namespaces()中,分别调用 create_nsproxy(), create_utsname(), create_ipcs(), create_pid_ns(), create_net_ns(), create_mnt_ns() 来创建 nsproxy 结构,uts,ipcs,pid,mnt,net。
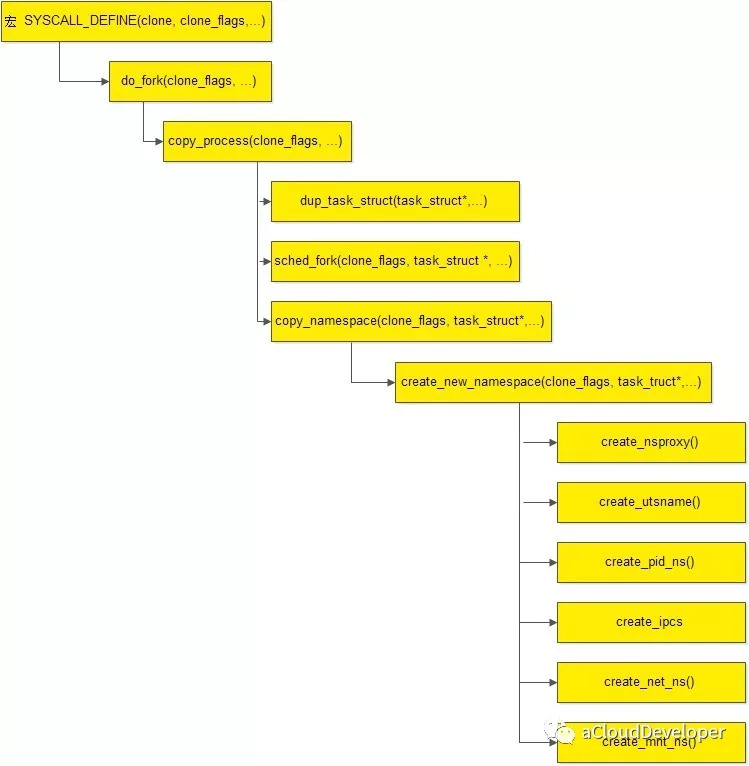
具体的函数我们就不再分析,基本到此为止,我们从子进程创建,到子进程相关的信息的初始化,包括文件系统,CPU,内存管理等,再到各个 namespace 的创建,都走了一遍,下面附上 namespace 创建的代码流程图。
mnt namespace:
1 | mnt namespace: |
可以看到,mount namespace 在新建时会新建一个新的 namespace,然后将父进程的 namespace 拷贝过来,并将 mount->mnt_ns 指向新的 namespace。接着设置进程的 root 路径以及当前路径到新的 namespace,然后为新进程设置新的 vfs 等。从这里就可以看出,在子进程中进行 mount 操作不会影响到父进程中的 mount 信息。
uts namespace:
1 | static inline struct uts_namespace *copy_utsname(unsigned long flags, |
uts namespace 直接返回父进程 namespace 信息。
ipc namespace:
1 | struct ipc_namespace *copy_ipcs(unsigned long flags, |
ipc namespace 如果是设置了参数 CLONE_NEWIPC,则直接返回父进程的 namespace,否则返回新创建的 namespace。
pid namespace:
1 | static inline struct pid_namespace *copy_pid_ns(unsigned long flags, |
pid namespace 直接返回父进程的 namespace。
net namespace
1 | static inline struct net *copy_net_ns(unsigned long flags, |
net namespace 也是直接返回父进程的 namespace。
OK,不知不觉写了这么多,但回头去看,这更像是代码走读,分析深度不够,更详细的大家可以参照源码,源码结构还是比较清晰的。
PS:文章未经我允许,不得转载,否则后果自负。
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。
文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
Docker 是“新瓶装旧酒”的产物,依赖于 Linux 内核技术 chroot 、namespace 和 cgroup。本篇先来看 namespace 技术。
Docker 和虚拟机技术一样,从操作系统级上实现了资源的隔离,它本质上是宿主机上的进程(容器进程),所以资源隔离主要就是指进程资源的隔离。实现资源隔离的核心技术就是 Linux namespace。这技术和很多语言的命名空间的设计思想是一致的(如 C++ 的 namespace)。
隔离意味着可以抽象出多个轻量级的内核(容器进程),这些进程可以充分利用宿主机的资源,宿主机有的资源容器进程都可以享有,但彼此之间是隔离的,同样,不同容器进程之间使用资源也是隔离的,这样,彼此之间进行相同的操作,都不会互相干扰,安全性得到保障。
为了支持这些特性,Linux namespace 实现了 6 项资源隔离,基本上涵盖了一个小型操作系统的运行要素,包括主机名、用户权限、文件系统、网络、进程号、进程间通信。
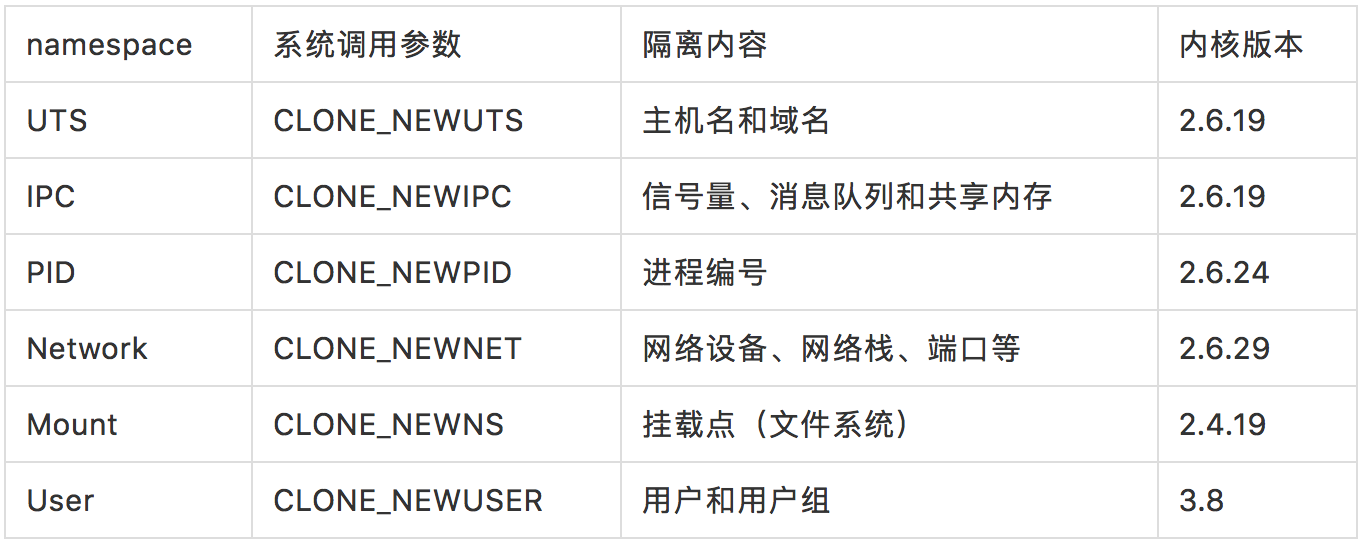
这 6 项资源隔离分别对应 6 种系统调用,通过传入上表中的参数,调用 clone() 函数来完成。1
int clone(int (*child_func)(void *), void *child_stack, int flags, void *arg);
clone() 函数相信大家都不陌生了,它是 fork() 函数更通用的实现方式,通过调用 clone(),并传入需要隔离资源对应的参数,就可以建立一个容器了(隔离什么我们自己控制)。
一个容器进程也可以再 clone() 出一个容器进程,这是容器的嵌套。
如果想要查看当前进程下有哪些 namespace 隔离,可以查看文件 /proc/[pid]/ns (注:该方法仅限于 3.8 版本以后的内核)。
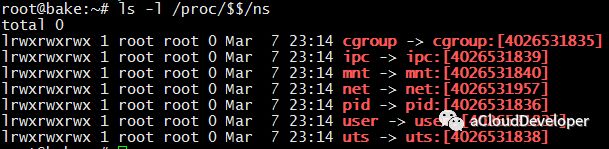
可以看到,每一项 namespace 都附带一个编号,这是唯一标识 namespace 的,如果两个进程指向的 namespace 编号相同,则表示它们同在该 namespace 下。同时也注意到,多了一个 cgroup,这个 namespace 是 4.6 版本的内核才支持的。Docker 目前对它的支持普及度还不高。所以我们暂时先不考虑它。
下面通过简单的代码来实现 6 种 namespace 的隔离效果,让大家有个直观的印象。
UTS namespace 提供了主机名和域名的隔离,这样每个容器就拥有独立的主机名和域名了,在网络上就可以被视为一个独立的节点,在容器中对 hostname 的命名不会对宿主机造成任何影响。
首先,先看总体的代码骨架:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#define STACK_SIZE (1024 * 1024)
static char container_stack[STACK_SIZE];
char* const container_args[] = {
"/bin/bash",
NULL
};
// 容器进程运行的程序主函数
int container_main(void *args)
{
printf("在容器进程中!\n");
execv(container_args[0], container_args); // 执行/bin/bash return 1;
}
int main(int args, char *argv[])
{
printf("程序开始\n");
// clone 容器进程
int container_pid = clone(container_main, container_stack + STACK_SIZE, SIGCHLD, NULL);
// 等待容器进程结束
waitpid(container_pid, NULL, 0);
return 0;
}
该程序骨架调用 clone() 函数实现了子进程的创建工作,并定义子进程的执行函数,clone() 第二个参数指定了子进程运行的栈空间大小,第三个参数即为创建不同 namespace 隔离的关键。
对于 UTS namespace,传入 CLONE_NEWUTS,如下:1
int container_pid = clone(container_main, container_stack + STACK_SIZE, SIGCHLD | CLONE_NEWUTS, NULL);
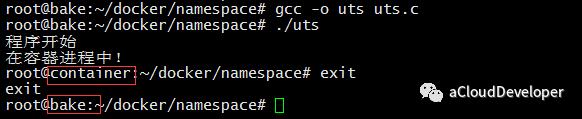
为了能够看出容器内和容器外主机名的变化,我们子进程执行函数中加入:1
sethostname("container", 9);
最终运行可以看到效果如下:
IPC namespace 实现了进程间通信的隔离,包括常见的几种进程间通信机制,如信号量,消息队列和共享内存。我们知道,要完成 IPC,需要申请一个全局唯一的标识符,即 IPC 标识符,所以 IPC 资源隔离主要完成的就是隔离 IPC 标识符。
同样,代码修改仅需要加入参数 CLONE_NEWIPC 即可,如下:1
int container_pid = clone(container_main, container_stack + STACK_SIZE, SIGCHLD | CLONE_NEWUTS | CLONE_NEWIPC, NULL);
为了看出变化,首先在宿主机上建立一个消息队列:
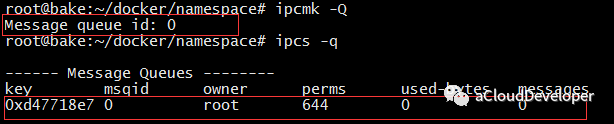
然后运行程序,进入容器查看 IPC,没有找到原先建立的 IPC 标识,达到了 IPC 隔离。
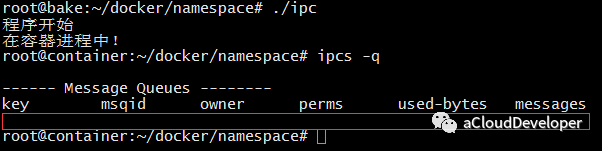
PID namespace 完成的是进程号的隔离,同样在 clone() 中加入 CLONE_NEWPID 参数,如:1
int container_pid = clone(container_main, container_stack + STACK_SIZE, SIGCHLD | CLONE_NEWUTS | CLONE_NEWIPC | CLONE_NEWPID, NULL);
效果如下,echo $$ 输出 shell 的 PID 号,发生了变化。
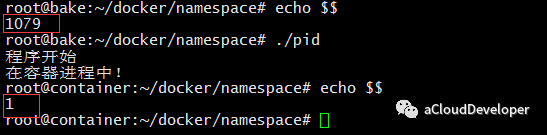
但是对于 ps/top 之类命令却没有改变:
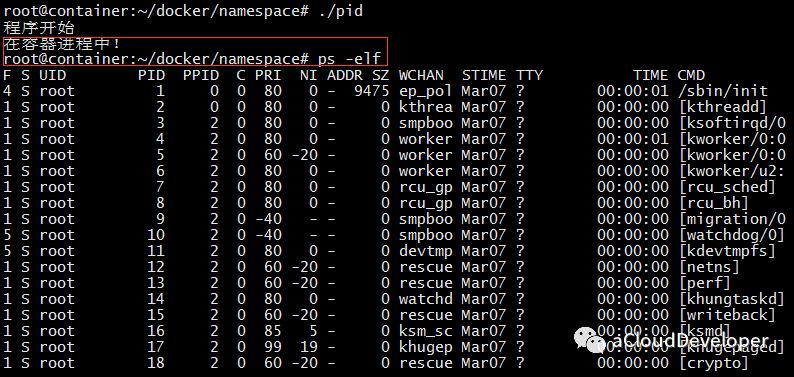
原因是 ps/top 之类的命令底层调用的是文件系统的 /proc 文件内容,由于 /proc 文件系统(procfs)还没有挂载到一个与原 /proc 不同的位置,自然在容器中显示的就是宿主机的进程。
我们可以通过在容器中重新挂载 /proc 即可实现隔离,如下:

这种方式会破坏 root namespace 中的文件系统,当退出容器时,如果 ps 会出现错误,只有再重新挂载一次 /proc 才能恢复。
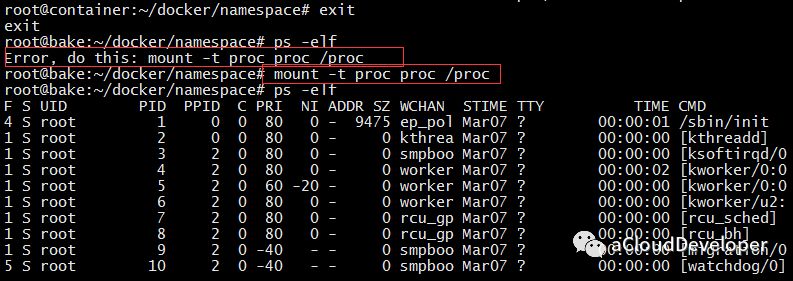
一劳永逸地解决这个问题最好的方法就是用接下来介绍的 mount namespace。
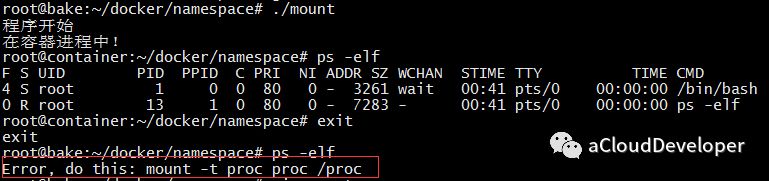
mount namespace 通过隔离文件系统的挂载点来达到对文件系统的隔离。我们依然在代码中加入 CLONE_NEWNS 参数:1
int container_pid = clone(container_main, container_stack + STACK_SIZE, SIGCHLD | CLONE_NEWUTS | CLONE_NEWIPC | CLONE_NEWPID | CLONE_NEWNS, NULL);
我验证的效果,当退出容器时,还是会有 mount 错误,这没道理,经多方查阅,没有找到问题的根源(有谁知道,可以留言指出)。
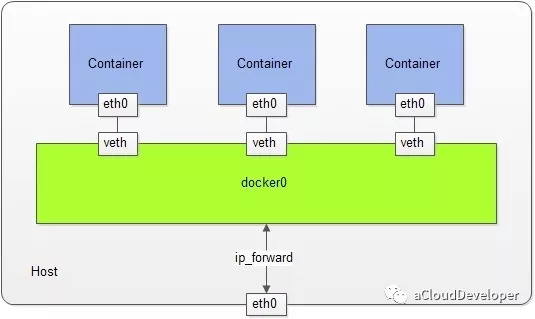
Network namespace 实现了网络资源的隔离,包括网络设备、IPv4 和 IPv6 协议栈,IP 路由表,防火墙,/proc/net 目录,/sys/class/net 目录,套接字等。
Network namespace 不同于其他 namespace 可以独立工作,要使得容器进程和宿主机或其他容器进程之间通信,需要某种“桥梁机制”来连接彼此(并没有真正的隔离),这是通过创建 veth pair (虚拟网络设备对,有两端,类似于管道,数据从一端传入能从另一端收到,反之亦然)来实现的。当建立 Network namespace 后,内核会首先建立一个 docker0 网桥,功能类似于 Bridge,用于建立各容器之间和宿主机之间的通信,具体就是分别将 veth pair 的两端分别绑定到 docker0 和新建的 namespace 中。
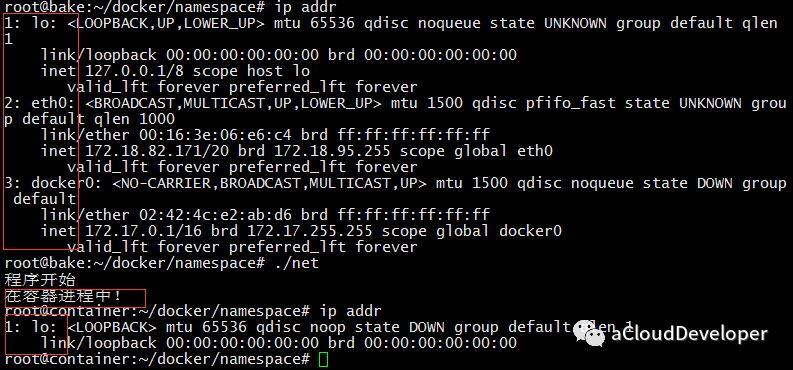
和其他 namespace 一样,Network namespace 的创建也是加入 CLONE_NEWNET 参数即可。我们可以简单验证下 IP 地址的情况,如下,IP 被隔离了。
User namespace 主要隔离了安全相关的标识符和属性,包括用户 ID、用户组 ID、root 目录、key 以及特殊权限。简单说,就是一个普通用户的进程通过 clone() 之后在新的 user namespace 中可以拥有不同的用户和用户组,比如可能是超级用户。
同样,可以加入 CLONE_NEWUSER 参数来创建一个 User namespace。然后再子进程执行函数中加入 getuid() 和 getpid() 得到 namespace 内部的 User ID,效果如下:
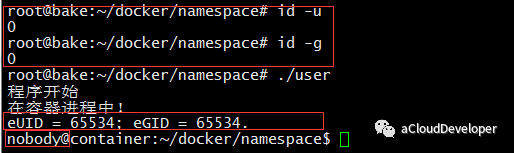
可以看到,容器内部看到的 UID 和 GID 和外部不同了,默认显示为 65534。这是因为容器找不到其真正的 UID ,所以设置上了最大的UID(其设置定义在/proc/sys/kernel/overflowuid)。另外就是用户变为了 nobody,不再是 root,达到了隔离。
以上就是对 6 种 namespace 从代码上简单直观地演示其实现,当然,真正的实现比这个要复杂得多,然后这 6 种 namespace 实际上也没有完全隔离 Linux 的资源,比如 SElinux、cgroup 以及 /sys 等目录下的资源没有隔离。目前,Docker 在很多方面已经做的很好,但相比虚拟机,仍然有许多安全性问题急需解决。
PS:文章未经我允许,不得转载,否则后果自负。
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。