文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!

Hi,大家好,我是 Linux云计算网络,欢迎大家和我一起学 K8S,这是系列第三篇。
每一种技术,为了描述清楚它的设计理念,都会自定义一堆概念或术语。在进入一门技术的研究之前,我们有必要扫清它的基本概念。
文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
Hi,大家好,我是 Linux云计算网络,欢迎大家和我一起学 K8S,这是系列第三篇。
每一种技术,为了描述清楚它的设计理念,都会自定义一堆概念或术语。在进入一门技术的研究之前,我们有必要扫清它的基本概念。
文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!

Hi,大家好,我是 Linux云计算网络!欢迎大家和我一起学习 K8S。
从前面的文章我们知道,Kubernetes 脱胎于 Google 的 Borg,Borg 在 Kubernetes 诞生之初已经在 Google 内部身经百战 10 余年,且不说它的历史源远流长,就凭它是出自 Google 那帮天才工程师之手,就知道它的学习难度不低。
文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!

Hi,大家好,我是 Linux云计算网络!欢迎大家和我一起学习 K8S。
大明王朝时期,明成祖朱棣为了发展海外贸易和建立自己的声望,派郑和七下西洋,创下了这段中国古代规模最大、船只最多(240多艘)、海员最多(2.7 万人)、时间最久的,比欧洲国家航海时间早半个多世纪的远洋航行壮举。
文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
Kubernetes 简称为 K8S。简单说,K8S 是一个用于容器集群的分布式系统架构。首先,它是基于容器技术,容器是和虚拟机并列的一种虚拟化技术,相比虚拟机来说,容器更加轻量,资源利用率更高,更适合于云原生应用。
文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
在孙悟空的七十二变中,我觉得最厉害的非分身能力莫属,这也是他百试不得其爽的终极大招,每每都能打得妖怪摸不着北。
文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
之前,我写过一篇「云计算技能图谱」的文章,涵盖了云计算领域绝大部分的分支,很多人看了表示不淡定了——学完这个要等到猴年马月!
其实那份图谱涉及到很多应用场景,比如说大数据,机器学习,这些是基于云计算引申的技术分支,底层用的是云计算的基础设施,但要说可不可以独立于云计算来做,可以,只是一个规模的问题罢了。
为了能给很多初学者一个好的引导,我重新整理了这份图谱,把一些相关联的技术分支去掉了,只保留了基础设施部分(包括计算、存储、网络、安全这几个部分)。如下:
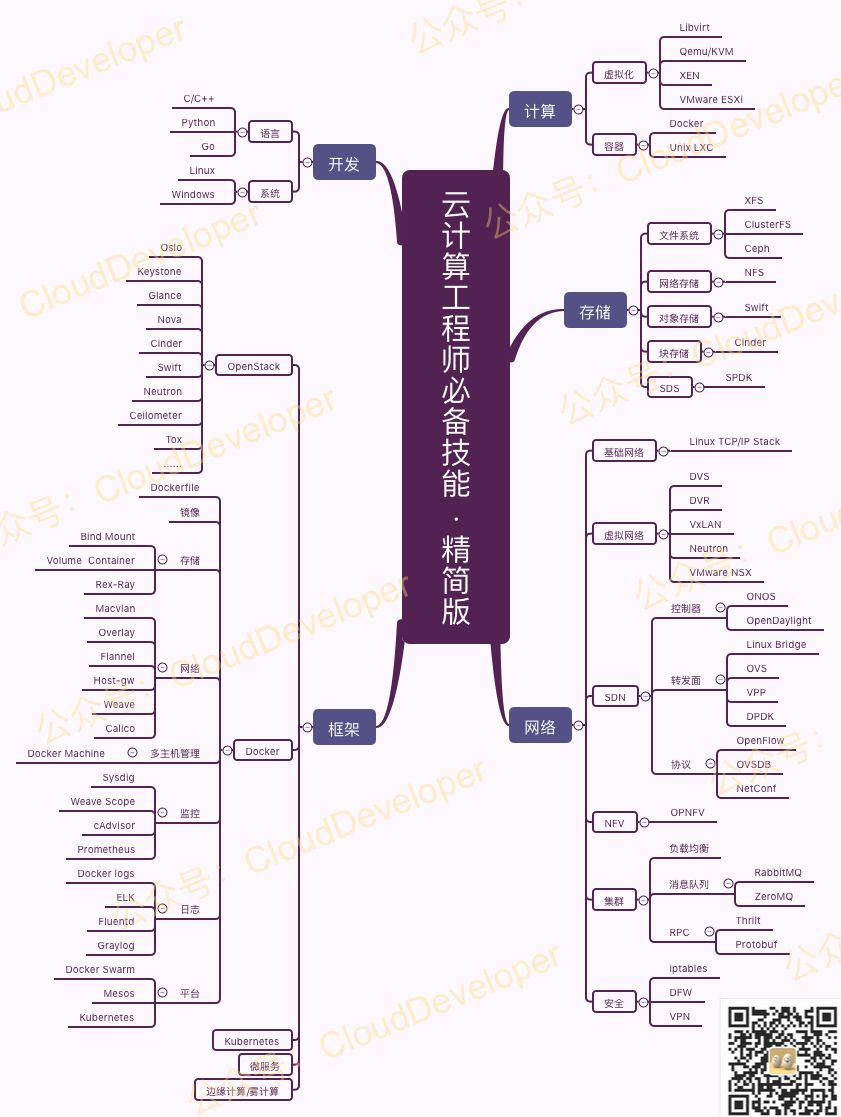
备注:图片为防抄袭迫不得已加水印,想要原图的可以加我微信私信我
这样来看,就显得精简多了。
可能你看到这个还是会很焦虑,其实大可不必焦虑,图谱更多告诉你的是这个领域有什么,至于做不做完全根据你自己的情况选择,比如你想做个 T 型人才 ,那就尽可能去学,想做个 I 型人才,那就专注在某一个领域就好了。这两者没有绝对的孰是孰非,最终都是要解决问题。就像一句话说的,不管黑猫白猫,能捉到老鼠的就是好猫。
我知道关注我的读者当中,什么人才都有,我目前知道的,有学生,有工作了好几年的老司机,也有博士,首先要感谢大家的关注,我相信大家关注我肯定是因为我的哪一篇文章触动了你或者对你有帮助才会关注的。
我想说,大家关注我肯定是没错的,我这个号专注的内容就是上面这份图谱提到的内容,你可以在这里看到最基础的开发实践内容(比如 Linux、C/C++、Python、Go 技术栈),也可以看到云计算框架的解读(比如 KVM,OpenStack,Docker,Kubernetes),还可以看到最前沿技术的探讨。当然也有一些非技术的内容,比如行业资讯,以及我一些不吐不快的碎碎念。
其实我进入这个领域也不算早,跟很多读者比起来,是不折不扣的菜鸟,但正因为我是菜鸟,我写出的文章才会通俗易懂,因为我要保证和我一样的菜鸟能听得懂,当然了,质量肯定是第一位的,你们要是看过我以前写的一些文章就知道质量如何了,绝对是很良心的分享。说这个主要是希望大家能多多向你身边的朋友推荐下我这个号,有更多的朋友加入,我的写作动力就越强,就能给你们输出更多更好的文章。
为了能让大家有一个交流的氛围,我建了一个群,想加入的可以后台回复“加群”。
另外,我这里还收藏了一套很有价值的技能图谱,包括上面说的很多细分领域,比如 Python、Docker、Kubernetes、DevOps,还有一些其他的分支,比如机器学习,大数据,架构师,运维,嵌入式等等等等,大概就像下面这样子:

这些资料是我精心为大家整理的,整理不易,大家如果需要,有一点点要求,只要你乐于分享即可。这里要说明一点,我觉得好的东西,就是要让更多的人看到,你可以说是诱导你分享,但扪心自问,遇到好的东西谁又不乐意分享呢,让你的朋友看到你分享好东西给他们又何尝不是一种快乐呢。
获取技能图谱方法:
PS:文章未经我允许,不得转载,否则后果自负。
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。

文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
前面单主机容器网络和多主机容器网络两篇文章,咱们已经从原理上总结了多种容器网络方案,也通过这篇文章探讨了容器网络的背后原理。本文再基于一个宏观的视角,对比几种网络方案,让大家有个完整的认识。
单主机网络就不多说了,因为也比较简单,我们重点对比几种多主机网络方案。
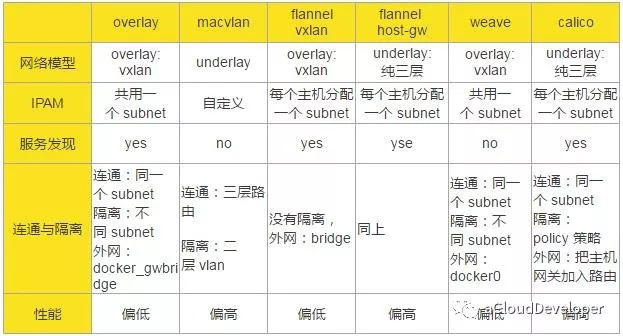
对比的维度有以下几种:网络模型,IP 地址池管理(IP Address Management,IPAM),服务发现,连通与隔离,性能。
网络模型指的是构成跨主机通信的网络结构和实现技术,比如是纯二层转发,还是纯三层转发;是 overlay 网络还是 underlay 网络等等。
IPAM 指的是如何管理容器网络的 IP 池。当容器集群比较大,管理的主机比较多的时候,如何分配各个主机上容器的 IP 是一个比较棘手的问题。Docker 网络有个 subnet 的概念,通常一个主机分配一个 subnet,但也有多个主机共用一个 subnet 的情况,具体的网络方案有不同的考量。具体看下面的表格总结。
服务发现本质上是一个分布式的 key-value 存储系统,用于跨主机通信时保存并同步各主机的网络信息,便于快速建立起各主机之间的网络连接。由于各网络方案实现上各有千秋,并不是所有的跨主机网络方案都要依据服务发现。
连通与隔离指的是容器跨主机之间是否能够互相通信,以及容器与外网(外网不一定指 Internet)之间如何通信。
性能具体指的是通信的时延,我们仅从各个网络方案的原理上来分析得出结论,所以这里的结论并不一定正确,因为不同的部署环境会对性能有一些影响,建议大家还是根据自己的环境动手实验验证为妙。
从原理上说,underlay 网络性能要优于 overlay 网络,因为 overlay 网络存在封包和拆包操作,存在额外的 CPU 和网络开销,所以,几种方案中,macvlan、flannel host-gw、calico 的性能会优于 overlay、flannel vxlan 和 weave。但是这个也不能作为最终生产环境采用的标准,因为 overlay 网络采用 vxlan 作为隧道的话,能支持更多的二层网段,安全性也更高,所以,需要综合考虑。
通过以上分析,我们可以得出以下的结论:
参考:
http://www.cnblogs.com/CloudMan6/p/7587532.html
PS:文章未经我允许,不得转载,否则后果自负。
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。
文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
知其然而不知其所以然,不知也。老古人说得多好,学知识不懂得知识背后的原理,等于白学。
通过前面两篇文章,我们知道了容器的单主机网络和多主机网络,对于这么多网络方案,我们看到对 Docker 的整体网络结构好像没有改动,都是水平扩展的,那 Docker 网络究竟是怎么集成这么多网络方案而不改变自身原有的结构呢?本文就来一探究竟。
要回答这个问题,得从 Docker 的总体框架说起。
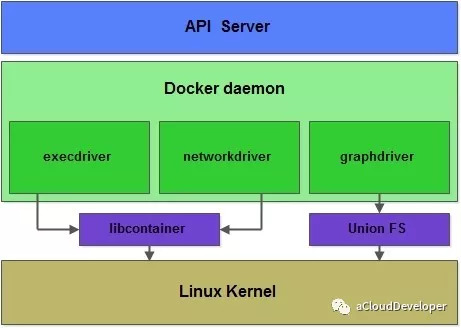
容器和虚拟机一样,都是虚拟化的产品,都包括计算虚拟化,存储虚拟化和 IO 虚拟化。容器作为轻量级的进程,不像虚拟机那般复杂,这三块分别靠三个 Driver 来完成的,execdriver 负责计算虚拟化,networkdriver 负责网络虚拟化,graphdriver 负责存储虚拟化。由此可见,Docker 靠 Driver 这种设计思想来支撑起它的基础平台,再往深了挖,它的每个子模块都随处可见这种设计思想,就网络这个子模块来看,也是如此。
期初的 Docker 网络子模块的代码是分散在 docker daemon 和 libcontainer 中的,libcontainer 是一个独立的容器管理包,execdriver 和 networkdriver 都是通过 libcontainer 来实现对容器的具体操作。
随着业务场景越来越复杂,这种内嵌的方式很难针对不同的网络场景进行扩展。后来,Docker 收购了一个做多主机网络解决方案的公司 SocketPlane,然后让那帮人专门来解决这个问题。这就是接下来要介绍的 libnetwork。
libnetwork 起初的做法很简单,就是将 docker engine 和 libcontainer 中网络相关的代码抽出来,合并成一个单独的库,做成网络抽象层,并对外提供 API。Docker 的愿景就是希望 libnetwork 能够做像 libcontainer 那样,成为一个多平台的容器网络基础包。
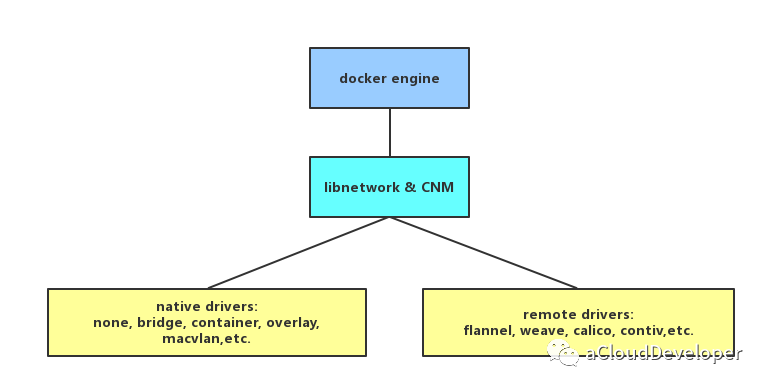
后来受一个 GitHub issue ( https://github.com/moby/moby/issues/9983) 的启发,libnetwork 引入容器网络模型(Container Network Model,CNM),该模型进一步对 Docker 的网络结构进行了细分,提出了三个概念:network、sandbox 和 endpoint。
network 是一个抽象的概念,你可以把它理解成一个网络的插件,或者是网络的 Driver,比如说单主机网络的 Driver 就有 none、host、bridge,joined container 这四种,多主机网络就有 overlay、macvlan、flannel 这些。network 可以独立出去做,只需调用 Docker 对外提供的 API 就可以作为插件集成到 Docker 网络中使用。
sandbox 实现了容器内部的网络栈,它定义容器的虚拟网卡,路由表和 DNS 等配置,其实就是一个标准的 linux network namespace 实现。
network 实现了一个第三方的网络栈,sandbox 则实现了容器内部的网络栈,那这两者怎么联系起来呢?答案就是通过 endpoint,endpoint 实现了 veth pair,一个 endpoint 就表示一对 veth pair,一端挂在容器中,另一端挂在 network 中。
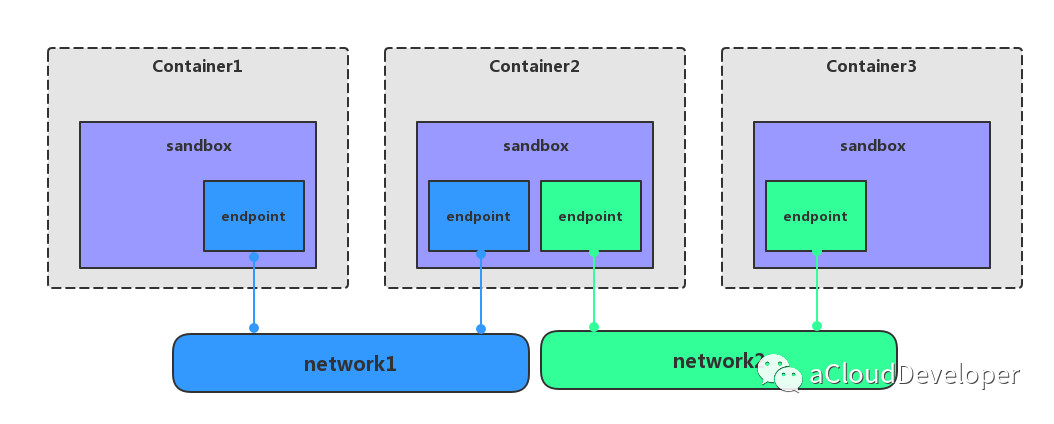
network、sandbox 和 endpoint 三者之间的关系:
一个 network 可以包含多个 endpoint,自然也就包含多个 sandbox。
一个 sandbox 可以包含多个 endpoint,可以属于多个 network。
一个 endpoint 只可以属于一个 network,并且只属于一个 sandbox。
如上图显示三个容器,每个容器一个 sandbox,除了第二个容器有两个 endpoint 分别接入 network1 和 network2 之外,其余 sandbox 都只有一个 endpoint 分别接入不同的 network。
到此,我们就可以解答文章开篇提到的问题,“不同的网络方案如何集成到 Docker 网络模型中而不改变原有结构?”
答案就是基于 libnetwork CNM,将各个网络模型以插件或 Driver 的形式集成到 Docker 网络中来,与 docker daemon 协同工作,实现容器网络。Docker 原生的 Driver 包括单主机的 none、bridge、joined container 和 多主机的 overlay、macvlan,第三方 Driver 就包括多主机的 flannel、weave、calico 等。
PS:文章未经我允许,不得转载,否则后果自负。
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。
文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
上篇文章介绍了容器网络的单主机网络,本文将进一步介绍多主机网络,也就是跨主机的网络。总结下来,多主机网络解决方案包括但不限于以下几种:overlay、macvlan、flannel、weave、cacico 等,下面将分别一一介绍这几种网络,
PS:本文仅从原理上对几种网络进行简单的对比总结,不涉及太多的细节。
俗称隧道网络,它是基于 VxLAN 协议来将二层数据包封装到 UDP 中进行传输的,目的是扩展二层网段,因为 VLAN 使用 12bit 标记 VLAN ID,最多支持 4094 个 VLAN,这对于大型云网络会成为瓶颈,而 VxLAN ID 使用 24bit 来标记,支持多达 16777216 个二层网段,所以 VxLAN 是扩展了 VLAN,也叫做大二层网络。
overlay 网络需要一个全局的“上帝”来记录它网络中的信息,比如主机地址,子网等,这个上帝在 Docker 中是由服务发现协议来完成的,服务发现本质上是一个 key-value 数据库,要使用它,首先需要向它告知(注册)一些必要的信息(如网络中需要通信的主机),然后它就会自动去收集、同步网络的信息,同时,还会维护一个 IP 地址池,分配给主机中的容器使用。Docker 中比较有名的服务发现有 Consul、Etcd 和 ZooKeeper。overlay 网络常用 Consul。
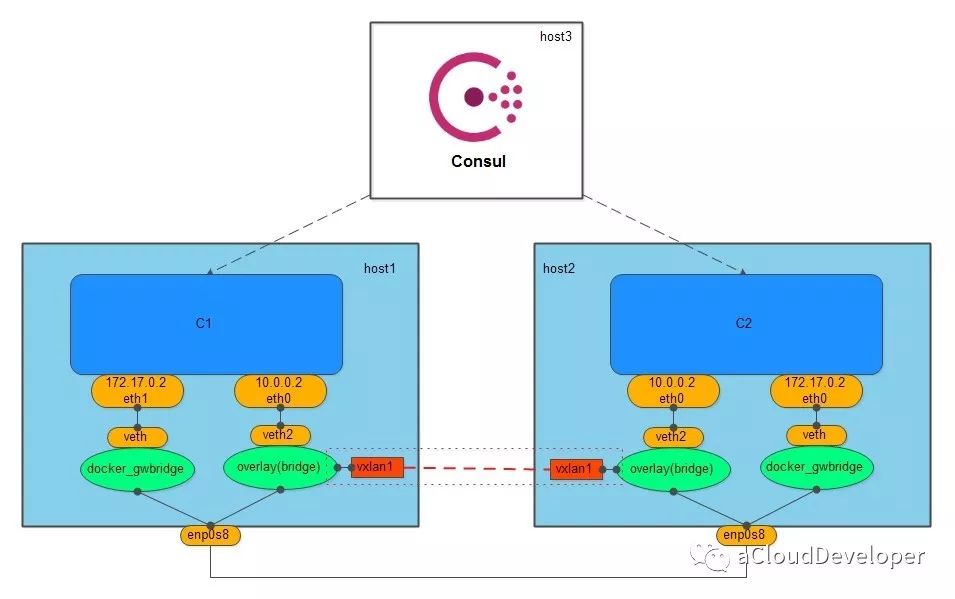
创建 overlay 网络会创建一个 Linux bridge br0,br0 会创建两个接口,一个 veth2 作为与容器的虚拟网卡相连的 veth pair,另一个 vxlan1 负责与其他 host 建立 VxLAN 隧道,跨主机的容器就通过这个隧道来进行通信。
为了保证 overlay 网络中的容器与外网互通,Docker 会创建另一个 Linux bridge docker_gwbridge,同样,该 bridge 也存在一对 veth pair,要与外围通信的容器可以通过这对 veth pair 到达 docker_gwbridge,进而通过主机 NAT 访问外网。
macvlan 就如它的名字一样,是一种网卡虚拟化技术,它能够将一个物理网卡虚拟出多个接口,每个接口都可以配置 MAC 地址,同样每个接口也可以配自己的 IP,每个接口就像交换机的端口一样,可以为它划分 VLAN。
macvlan 的做法其实就是将这些虚拟出来的接口与 Docker 容器直连来达到通信的目的。一个 macvlan 网络对应一个接口,不同的 macvlan 网络分配不同的子网,因此,相同的 macvlan 之间可以互相通信,不同的 macvlan 网络之间在二层上不能通信,需要借助三层的路由器才能完成通信,如下,显示的就是两个不同的 macvlan 网络之间的通信流程。
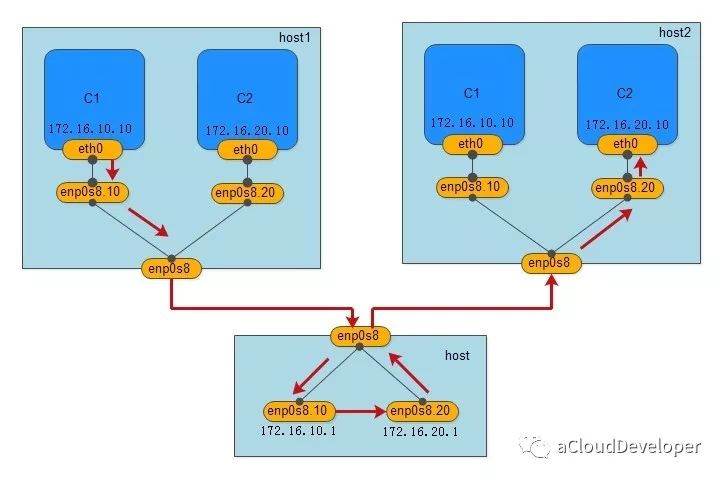
我们用一个 Linux 主机,通过配置其路由表和 iptables,将其配成一个路由器(当然是虚拟的),就可以完成不同 macvlan 网络之间的数据交换,当然用物理路由器也是没毛病的。
flannel 网络也需要借助一个全局的上帝来同步网络信息,一般使用的是 etcd。
flannel 网络不会创建新的 bridge,而是用默认的 docker0,但创建 flannel 网络会在主机上创建一个虚拟网卡,挂在 docker0 上,用于跨主机通信。
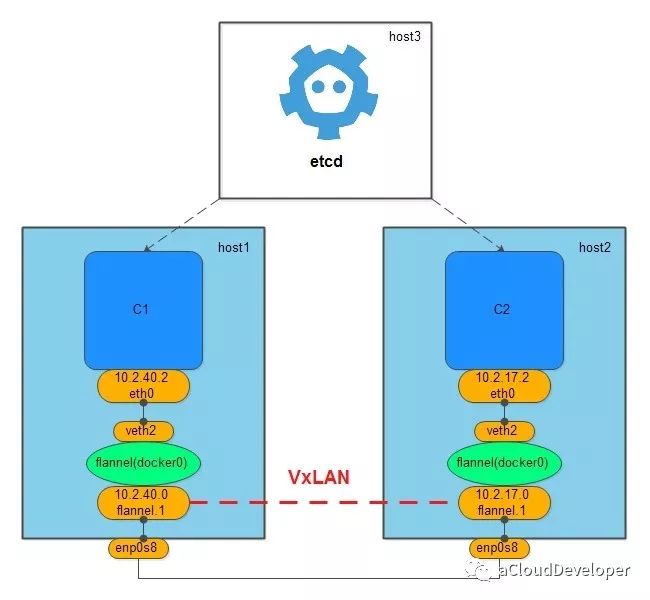
组件方式让 flannel 多了几分灵活性,它可以使用二层的 VxLAN 隧道来封装数据包完成跨主机通信,也可以使用纯三层的方案来通信,比如 host-gw,只需修改一个配置文件就可以完成转化。
weave 网络没有借助服务发现协议,也没有 macvlan 那样的虚拟化技术,只需要在不同主机上启动 weave 组件就可以完成通信。
创建 weave 网络会创建两个网桥,一个是 Linux bridge weave,一个是 datapath,也就是 OVS,weave 负责将容器加入 weave 网络中,OVS 负责将跨主机通信的数据包封装成 VxLAN 包进行隧道传输。
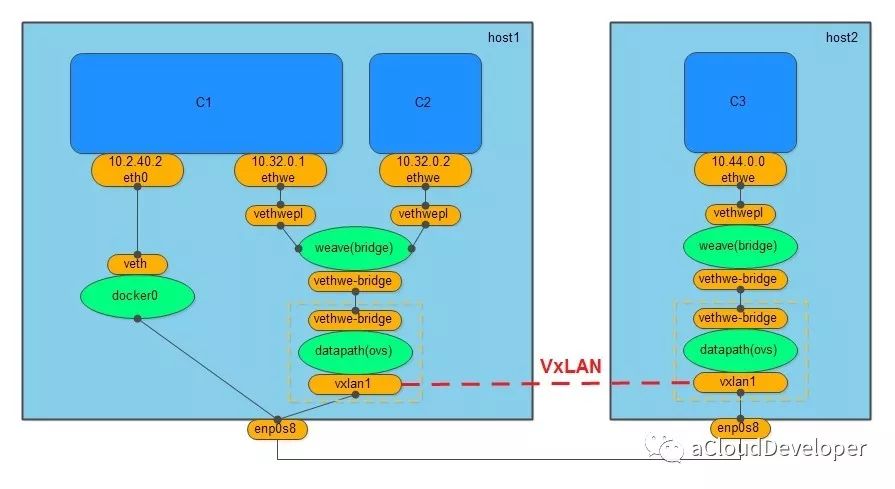
同样,weave 网络也不支持与外网通信,Docker 提供 docker0 来满足这个需求。
weave 网络通过组件化的方式使得网络分层比较清晰,两个网桥的分工也比较明确,一个用于跨主机通信,相当于一个路由器,一个负责将本地网络加入 weave 网络。
calico 是一个纯三层的网络,它没有创建任何的网桥,它之所以能完成跨主机的通信,是因为它记住 etcd 将网络中各网段的路由信息写进了主机中,然后创建的一对的 veth pair,一块留在容器的 network namespace 中,一块成了主机中的虚拟网卡,加入到主机路由表中,从而打通不同主机中的容器通信。
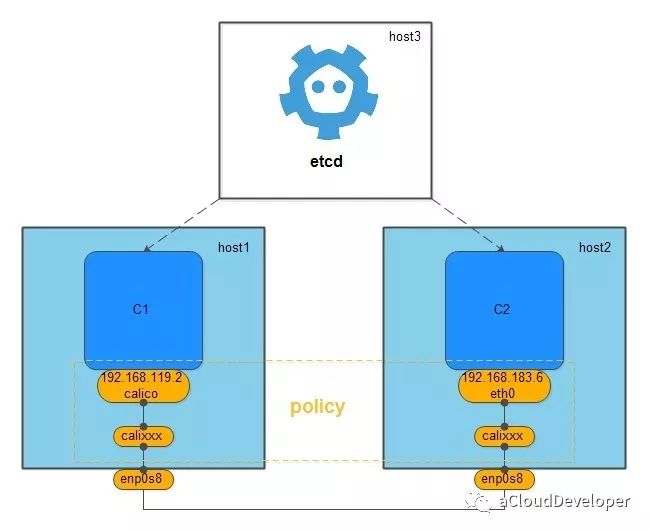
calico 相较其他几个网络方案最大优点是它提供 policy 机制,用户可以根据自己的需求自定义 policy,一个 policy 可能对应一条 ACL,用于控制进出容器的数据包,比如我们建立了多个 calico 网络,想控制其中几个网络可以互通,其余不能互通,就可以修改 policy 的配置文件来满足要求,这种方式大大增加了网络连通和隔离的灵活性。
1、除了以上的几种方案,跨主机容器网络方案还有很多,比如:Romana,Contiv 等,本文就不作过多展开了,大家感兴趣可以查阅相关资料了解。
2、跨主机的容器网络通常要为不同主机的容器维护一个 IP 池,所以大多方案需要借助第三方的服务发现方案。
3、跨主机容器网络按传输方式可以分为纯二层网络,隧道网络(大二层网络),以及纯三层网络。
PS:文章未经我允许,不得转载,否则后果自负。
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。
文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
在看本文之前,建议先看 virtio 简介,vhost 简介,vhost-user 简介。
virtio-user 是 DPDK 针对特定场景提出的一种解决方案,它主要有两种场景的用途,一种是用于 DPDK 应用容器对 virtio 的支持,这是 DPDK v16.07 开始支持的;另一种是用于和内核通信,这是 DPDK v17.02 推出的。
我们知道,对于虚拟机,有 virtio 这套半虚拟化的标准协议来指导虚拟机和宿主机之间的通信,但对于容器的环境,直接沿用 virtio 是不行的,原因是虚拟机是通过 Qemu 来模拟的,Qemu 会将它虚拟出的整个 KVM 虚拟机的信息共享给宿主机,但对于 DPDK 加速的容器化环境来说显然是不合理的。因为 DPDK 容器与宿主机的通信只用得到虚拟内存中的大页内存部分,其他都是用不到的,全部共享也没有任何意义,DPDK 主要基于大页内存来收发数据包的。
所以,virtio_user 其实就是在 virtio PMD 的基础上进行了少量修改形成的,简单来说,就是添加大页共享的部分逻辑,并精简了整块共享内存部分的逻辑。
有兴趣可以对照 /driver/net/virtio 中的代码和 DPDK virtio_user 代码,其实大部分是相同的。
从 DPDK 的角度看,virtio_user 是作为一个虚拟设备(vdev)来加载的,它充当的是一个 virtio 前端驱动,与之对应的后端通信驱动,是用户态的 vhost_user,在使用的时候,我们只需要定义好相应的适配接口即可,如下:
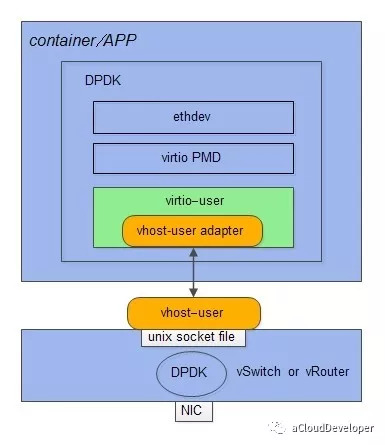
vhost 和 vhost_user 本质上是采用共享内存的 IPC 方式,通过在 host 端创建 vhost_user 共享内存文件,然后 virtio_user 启动的时候指定该文件即可,如:1
2
3
41)首先创建 vhost_user 共享内存文件
--vdev 'eth_vhost_user0,iface=/tmp/vhost_user0'
2)启动 virtio_user 指定文件路径
--vdev=virtio_user0,path=/tmp/vhost_user0
virtio_user 的一个用途就是作为 exception path 用于与内核通信。我们知道,DPDK 是旁路内核的转包方案,这也是它高性能的原因,但有些时候从 DPDK 收到的包(如控制报文)需要丢到内核网络协议栈去做进一步的处理,这个路径在 DPDK 中就被称为 exception path。
在这之前,已经存在几种 exception path 的方案,如传统的 Tun/Tap,KNI(Kernel NIC Interface),AF_Packet 以及基于 SR-IOV 的 Flow Bifurcation。这些方案就不做过多介绍了,感兴趣的可看 DPDK 官网,上面都有介绍。
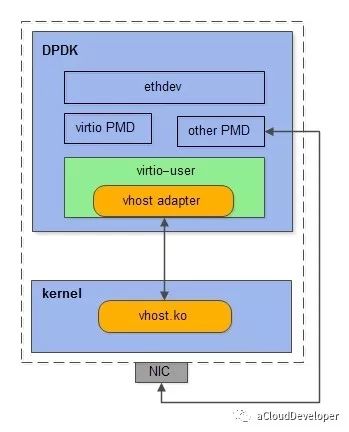
和容器网络的方案使用 vhost_user 作为后端驱动一样,要使得 virtio_user 和内核通信,只需加载内核模块 vhost.ko,让它充当的是 virtio_user 的后端通信驱动即可。
所以,我们可以看到,其实这两种方案本质上是一样,只是换了个后端驱动而已,这也是 virtio 的优势所在,定义一套通用的接口标准,需要什么类型的通信方式只需加载相应驱动即可,改动非常少,扩展性非常高。
PS:文章未经我允许,不得转载,否则后果自负。
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。