文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
本文的一些概念依赖于上一篇 “CPU 拓扑:从 SMP 谈到 NUMA (理论篇)”,如果你对这块还没有概念,建议看完那篇再来看,如果对这块有自己独到的见解,欢迎探讨。
本文主要会侧重 NUMA 这块,我会通过自己的环境验证 NUMA 的几个概念,以便对 NUMA 的架构有个较深的印象。
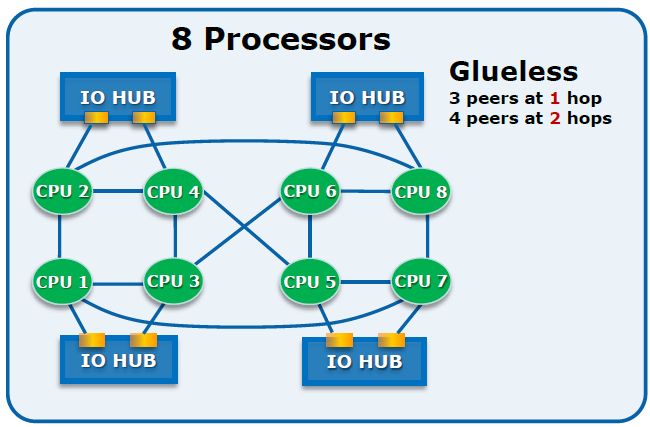
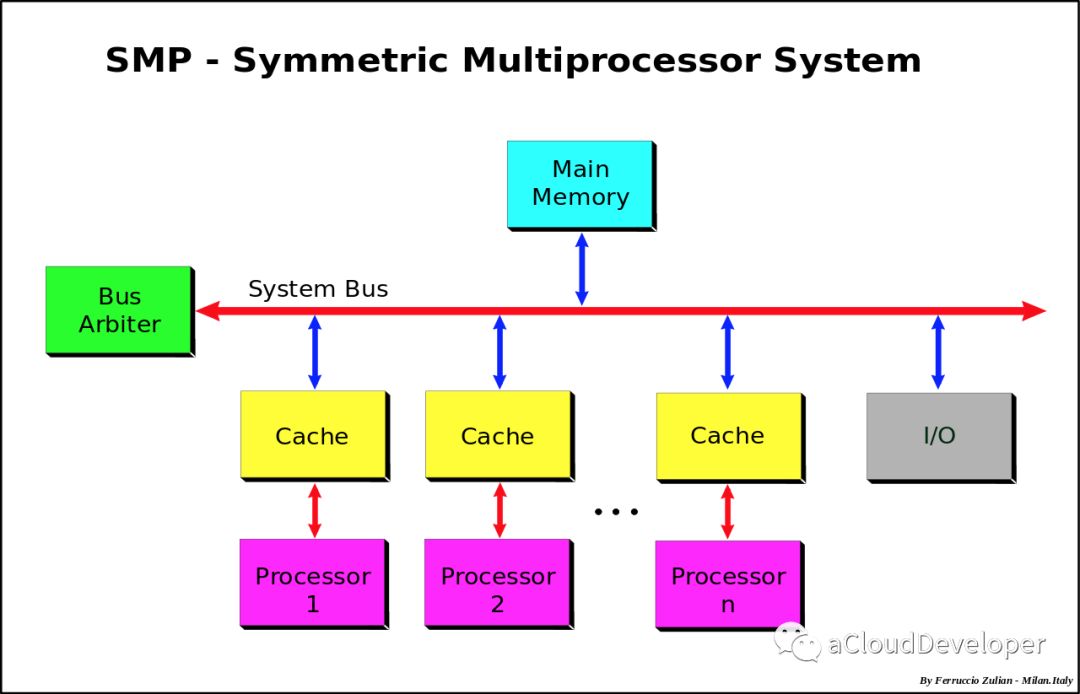
NUMA 的几个概念:Node,Socket,Core,Thread
NUMA 技术的主要思想是将 CPU 进行分组,Node 即是分组的抽象,一个 Node 表示一个分组,一个分组可以由多个 CPU 组成。每个 Node 都有自己的本地资源,包括内存、IO 等。每个 Node 之间通过互联模块(QPI)进行通信,因此每个 Node 除了可以访问自己的本地内存之外,还可以访问远端 Node 的内存,只不过性能会差一些,一般用 distance 这个抽象的概念来表示各个 Node 之间互访资源的开销。
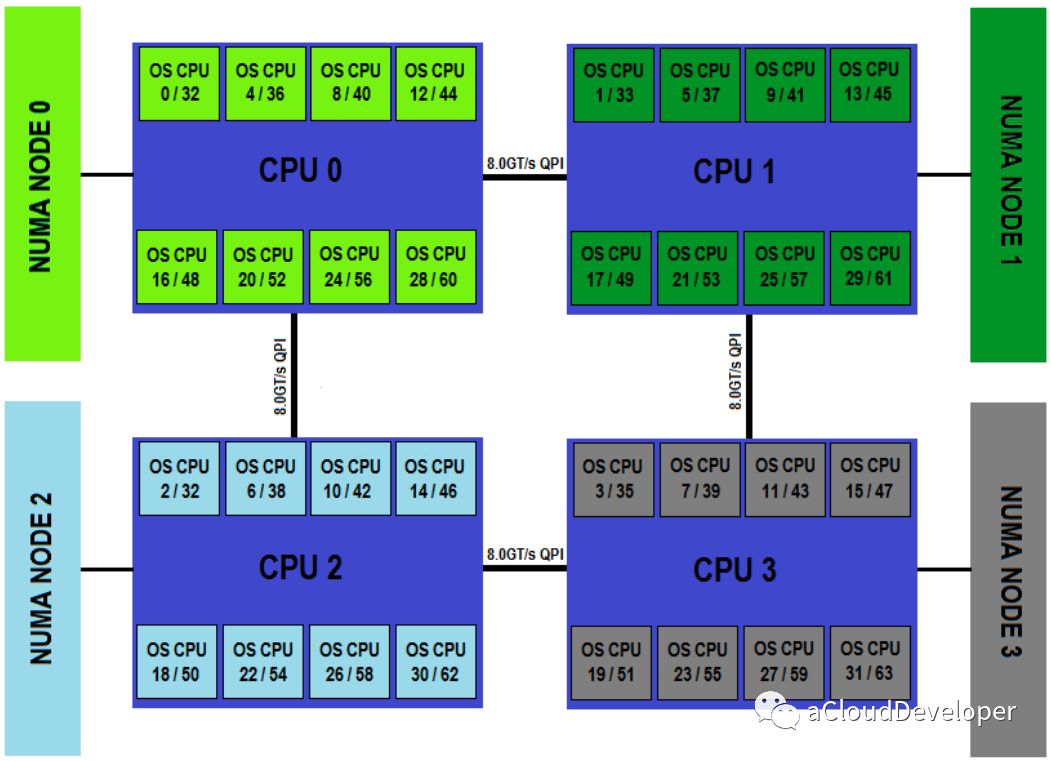
Node 是一个逻辑上的概念,与之相对的 Socket,是物理上的概念。它表示一颗物理 CPU 的封装,是主板上的 CPU 插槽,所以,一般就称之为插槽(敲黑板,这 Y 不是套接字吗?emmm……)
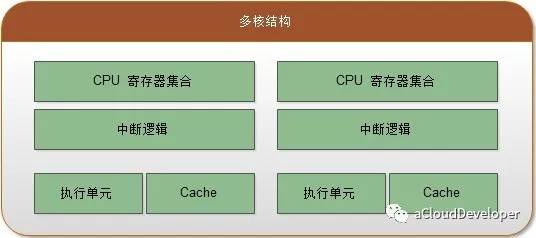
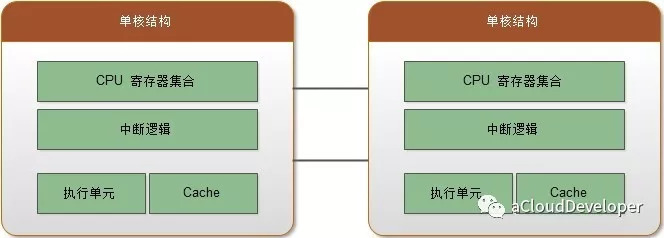
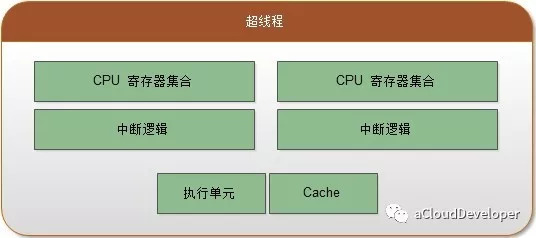
Core 就是 Socket 里独立的一组程序执行单元,称之为物理核。有了物理核,自然就有逻辑核,Thread 就是逻辑核。更专业的说法应该称之为超线程。
超线程是为了进一步提高 CPU 的处理能力,Intel 提出的新型技术。它能够将一个 Core 从逻辑上划分成多个逻辑核(一般是两个),每个逻辑核有独立的寄存器和中断逻辑,但是一个 Core 上的多个逻辑核共享 Core 内的执行单元和 Cache,频繁调度可能会引起资源竞争,影响性能。超线程必须要 CPU 支持才能开启。
综上所述,一个 NUMA Node 可以有一个或者多个 Socket,每个 Socket 也可以有一个(单核)或者多个(多核)Core,一个 Core 如果打开超线程,则会变成两个逻辑核(Logical Processor,简称 Processor)。
所以,几个概念从大到小排序依次是:
Node > Socket > Core > Processor。
验证 CPU 拓扑
了解了以上基本概念,下面在实际环境中查看这些概念并验证。
Node
用 numactl --hardware 查看当前系统的 NUMA Node(numactl 是设定进程 NUMA 策略的命令行工具):1
2
3
4
5
6
7
8
9
10
11
12Linux # numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 12 13 14 15 16 17
node 0 size: 49043 MB
node 0 free: 20781 MB
node 1 cpus: 6 7 8 9 10 11 18 19 20 21 22 23
node 1 size: 49152 MB
node 1 free: 31014 MB
node distances:
node 0 1
0: 10 21
1: 21 10
可以得出的信息有:1)系统的 Node 数为 2;2)每个 Node 包含的 Processor 数为 12;3)每个 Node 的总内存大小和空闲内存大小;4)每个 Node 之间的 distance。
还可以查看 /sys/devices/system/node/ 目录,这里记录着具体哪些 Node。
Socket
/proc/cpuinfo 中记录着 Socket 信息,用 “physical id” 表示,可以用 cat /proc/cpuinfo | grep "physical id" 查看:
1 | Linux # cat /proc/cpuinfo | grep "physical id" |
可以看到有 2 个 Socket,我们还可以查看以下这几种变种:
1)查看有几个 Socket1
2
3
4Linux # grep 'physical id' /proc/cpuinfo | awk -F: '{print $2 | "sort -un"}'
0
1
1 | Linux # grep 'physical id' /proc/cpuinfo | awk -F: '{print $2 | "sort -un"}' | wc -l |
2)查看每个 Socket 有几个 Processor1
2
3
4Linux # grep 'physical id' /proc/cpuinfo | awk -F: '{print $2}' | sort | uniq -c
12 0
12 1
3)查看每个 Socket 有哪几个 Processor1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18Linux # awk -F: '{
> if ($1 ~ /processor/) {
> gsub(/ /,"",$2);
> p_id=$2;
> } else if ($1 ~ /physical id/){
> gsub(/ /,"",$2);
> s_id=$2;
> arr[s_id]=arr[s_id] " " p_id
> }
> }
>
> END{
> for (i in arr)
> print arr[i];
> }' /proc/cpuinfo | cut -c2-
0 1 2 3 4 5 12 13 14 15 16 17
6 7 8 9 10 11 18 19 20 21 22 23
Core
同样在 /proc/cpuinfo 中查看 Core 信息:
1 | Linux # cat /proc/cpuinfo |grep "core id" | sort -u |
上面的结果表明一个 Socket 有 5 个 Core。上面查到有 2 个 Socket,则一共就有 10 个 Core。
Processor
上面查看 Socket 信息时已经能够得到 Processor 的信息,总共有 24 个 Processor,不过也可以直接从 /proc/cpuinfo 中获取:
1)获取总的 Processor 数,查看 “processor” 字段:1
2
3Linux # cat /proc/cpuinfo | grep "processor" | wc -l
24
2)获取每个 Socket 的 Processor 数,查看 “siblings” 字段:1
2
3Linux # cat /proc/cpuinfo | grep "siblings" | sort -u
12
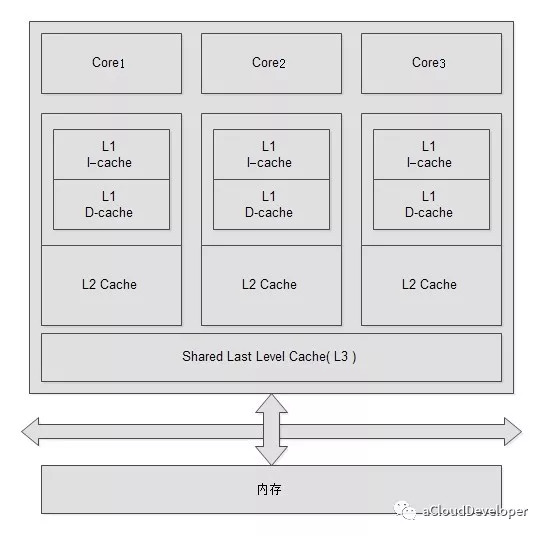
Cache
Cache 也一样通过 /proc/cpuinfo 查看:1
2
3
4
5processor : 0
cache size : 15360 KB
cache_alignment : 64
不过这里的值 cache size 比较粗略,我们并不知道这个值是哪一级的 Cache 值(L1?L2?L3?),这种方法不能确定,我们换一种方法。
其实详细的 Cache 信息可以通过 sysfs 查看,如下:
比如查看 cpu0 的 cache 情况:1
2
3Linux # ls /sys/devices/system/cpu/cpu0/cache/
index0/ index1/ index2/ index3/
其中包含四个目录:
index0 存 L1 数据 Cache,index1 存 L1 指令 Cache,index2 存 L2 Cache,index3 存 L3 Cache。每个目录里面包含一堆描述 Cache 信息的文件。我们选 index0 具体看下:
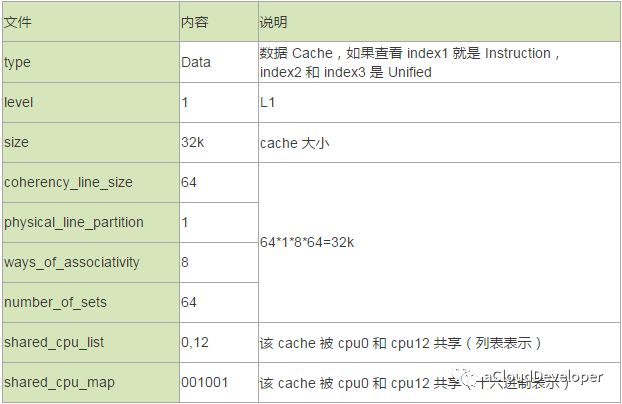
其中,shared_cpu_list 和 shared_cpu_map 表示意思是一样的,都表示该 cache 被哪几个 processor 共享。对 shared_cpu_map 具体解释一下。
这个值表面上看是二进制,但其实是 16 进制,每个数字有 4 个bit,代表 4 个 cpu。比如上面的 001001 拆开后是:1
0000 0000 0001 0000 0000 0001,1 bit 处即对应 cpu 标号,即 cpu0 和 cpu12。
同样我们可以对其他 index 进行统计,可以得出:
/proc/cpuinfo 中的 cache size 对应的 L3 Cache size。
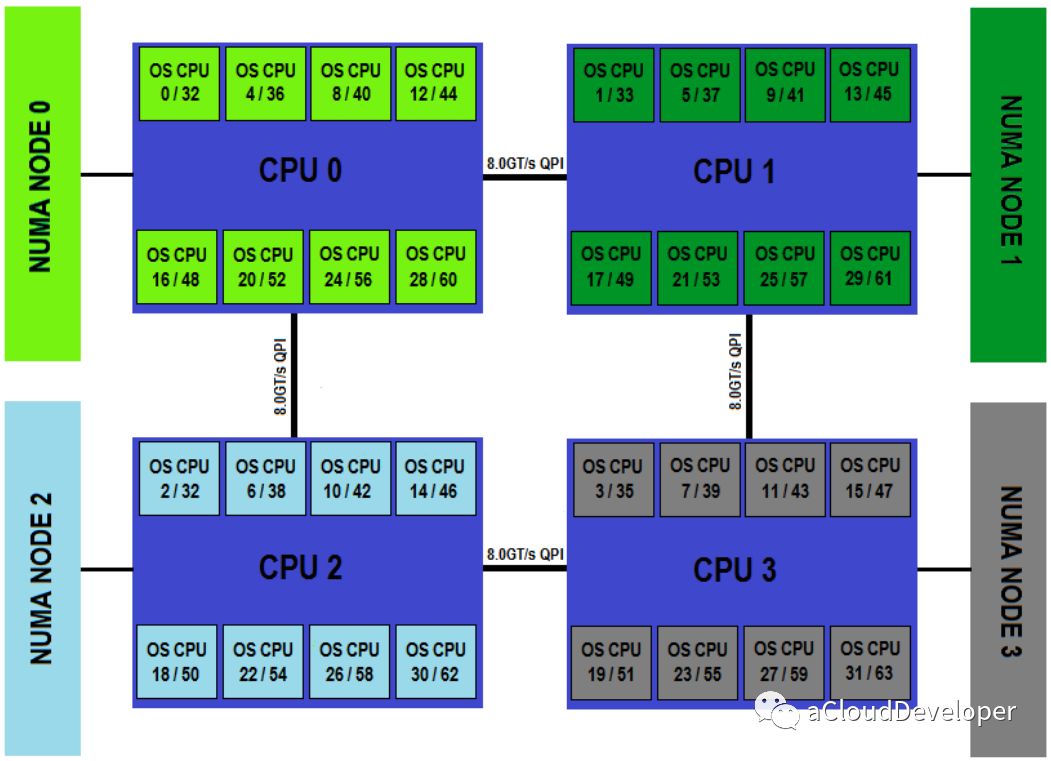
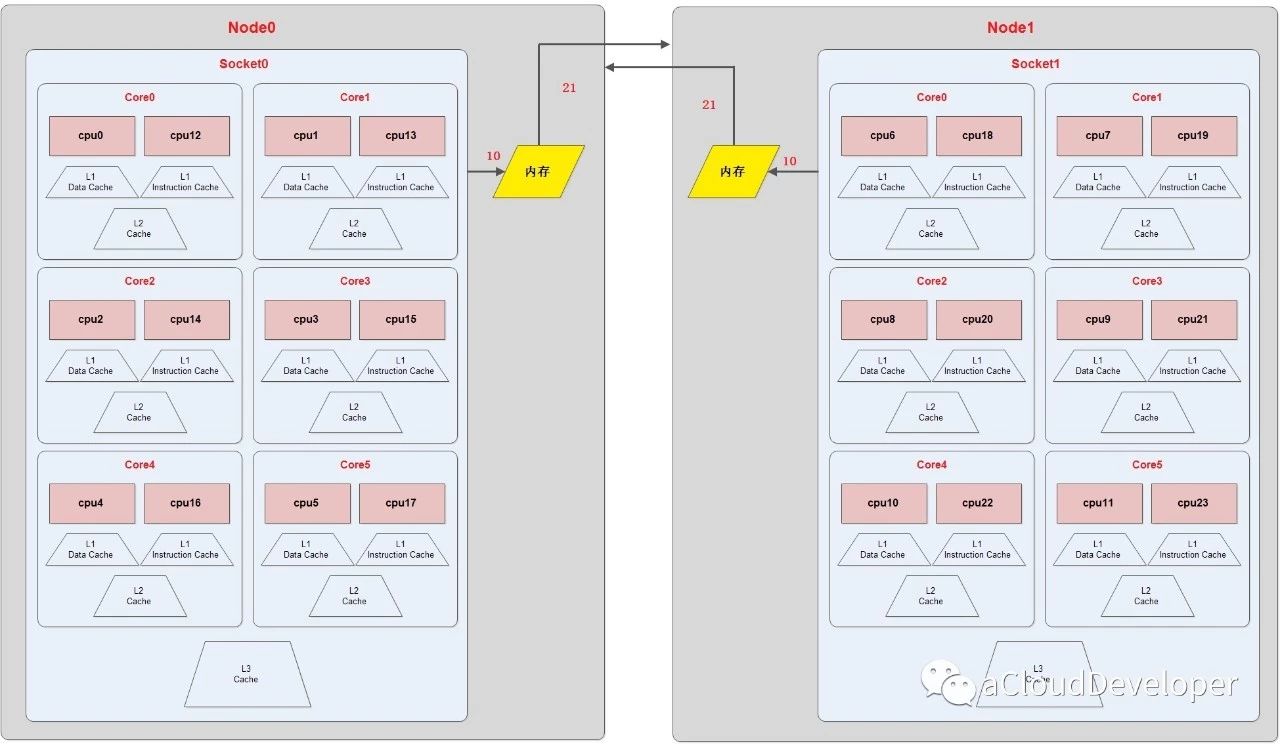
最后,综合以上所有信息我们可以绘制出一下的 CPU 拓扑图:
我们发现以上命令用得不太顺手,要获取多个数据需要输入多条命令,能不能一条命令就搞定,当然是有的,lscpu 就可以做到,如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23Linux # lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 24 //共有24个逻辑CPU(threads)
On-line CPU(s) list: 0-23
Thread(s) per core: 2 //每个 Core 有 2 个 Threads
Core(s) per socket: 12 //每个 Socket 有 12 个 Threads
Socket(s): 2 //共有 2 个 Sockets
NUMA node(s): 2 //共有 2 个 Nodes
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Stepping: 2
CPU MHz: 2401.000
BogoMIPS: 4803.16
Virtualization: VT-x
L1d cache: 32K //L1 data cache 32k
L1 cache: 32K //L1 instruction cache 32k
L2 cache: 256K //L2 instruction cache 256k
L3 cache: 15360K //L3 instruction cache 15M
NUMA node0 CPU(s): 0-5,12-17
NUMA node1 CPU(s): 6-11,18-23
当然了,没有完美的命令,lscpu 也只能显示一些宽泛的信息,只是相对比较全面而已,更详细的信息,比如 Core 和 Cache 信息就得借助 cpuinfo 和 sysfs 了。
下面给大家提供一个脚本,能够比较直观的显示以上所有信息,有 shell 版的和 python 版的(不是我写的,文末附上了引用出处)。
大家有需要可以回复 “CPU” 获取,我就不贴出来了,显示的结果大概就是长下面这个样子:
python 版:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24============================================================
Core and Socket Information (as reported by '/proc/cpuinfo')
============================================================
cores = [0, 1, 2, 3, 4, 5]
sockets = [0, 1]
Socket 0 Socket 1
-------- --------
Core 0 [0, 12] [6, 18]
Core 1 [1, 13] [7, 19]
Core 2 [2, 14] [8, 20]
Core 3 [3, 15] [9, 21]
Core 4 [4, 16] [10, 22]
Core 5 [5, 17] [11, 23]
Reference:
- 玩转 CPU 拓扑:
http://blog.itpub.net/645199/viewspace-1421876/ - NUMA 体系结构详解
https://blog.csdn.net/ustc_dylan/article/details/45667227(shell 代码引用) - dpdk 源代码(python 代码引用)
PS:文章未经我允许,不得转载,否则后果自负。
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。