本文首发于我的公众号 「Linux云计算网络」(id: cloud_dev) ,专注于干货分享,号内有大量书籍和视频资源,后台回复「1024」即可领取,欢迎大家关注,二维码文末可以扫。
在这篇文章中,我们已经介绍了 tap/tun 的基本原理,本文将介绍如何使用工具 tunctl和 ip tuntap 来创建并使用 tap/tun 设备。
本文首发于我的公众号 「Linux云计算网络」(id: cloud_dev) ,专注于干货分享,号内有大量书籍和视频资源,后台回复「1024」即可领取,欢迎大家关注,二维码文末可以扫。
在这篇文章中,我们已经介绍了 tap/tun 的基本原理,本文将介绍如何使用工具 tunctl和 ip tuntap 来创建并使用 tap/tun 设备。
本文首发于我的公众号 「Linux云计算网络」(id: cloud_dev) ,专注于干货分享,号内有大量书籍和视频资源,后台回复「1024」即可领取,欢迎大家关注,二维码文末可以扫。
在云计算时代,虚拟机和容器已经成为标配。它们背后的网络管理都离不开一样东西,就是虚拟网络设备,或者叫虚拟网卡,tap/tun 就是在云计算时代非常重要的虚拟网络网卡。
tap/tun 是 Linux 内核 2.4.x 版本之后实现的虚拟网络设备,不同于物理网卡靠硬件网路板卡实现,tap/tun 虚拟网卡完全由软件来实现,功能和硬件实现完全没有差别,它们都属于网络设备,都可以配置 IP,都归 Linux 网络设备管理模块统一管理。
本文首发于我的公众号 「Linux云计算网络」(id: cloud_dev) ,专注于干货分享,号内有大量书籍和视频资源,后台回复「1024」即可领取,欢迎大家关注,二维码文末可以扫。
本文通过 IP 命令操作来简单介绍 network namespace 的基本概念和用法。
深入了解可以看看我之前写的两篇文章 Docker 基础技术之 Linux namespace 详解 和 Docker 基础技术之 Linux namespace 源码分析。
和 network namespace 相关的操作的子命令是 ip netns 。
本文首发于我的公众号 「Linux云计算网络」(id: cloud_dev) ,专注于干货分享,号内有 10T 书籍和视频资源,后台回复「1024」即可免费领取,欢迎大家关注,二维码文末可以扫。
后台回复「加群」,带你进入高手如云交流群。
我的公众号 「Linux云计算网络」(id: cloud_dev) ,号内有 10T 书籍和视频资源,后台回复 「1024」 即可免费领取,分享的内容包括但不限于 Linux、网络、云计算虚拟化、容器Docker、OpenStack、Kubernetes、工具、SDN、OVS、DPDK、Go、Python、C/C++编程技术等内容,欢迎大家关注。
本文首发于我的公众号 「Linux云计算网络」 ,专注于干货分享,号内有大量书籍和视频资源,后台回复「1024」即可领取,欢迎大家关注,二维码文末可以扫。
环境:ubuntu 16.04 环境(物理 or 虚拟)
确认 CPU 是否支持虚拟化:
1 | # egrep -o '(vmx|svm)' /proc/cpuinfo |
如果不支持,开启 KVM 嵌套虚拟化之后再重启。
文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
如下图所示,从宏观上来看,Linux 操作系统的体系架构分为用户态和内核态(或者用户空间和内核)。
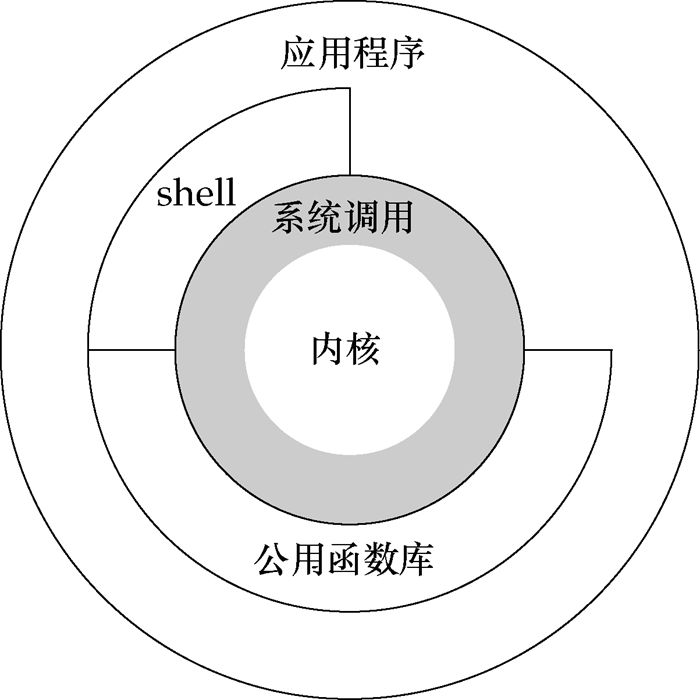
内核从本质上看是一种软件——控制计算机的硬件资源,并提供上层应用程序运行的环境。用户态即上层应用程序的活动空间,应用程序的执行必须依托于内核提供的资源,包括 CPU 资源、存储资源、I/O 资源等。为了使上层应用能够访问到这些资源,内核必须为上层应用提供访问的接口:即系统调用。
系统调用是操作系统的最小功能单位,这些系统调用根据不同的应用场景可以进行扩展和裁剪,现在各种版本的 Unix 实现都提供了不同数量的系统调用,如 Linux 的不同版本提供了 240-260 个系统调用,FreeBSD 大约提供了 320 个(reference:UNIX 环境高级编程)。
我们可以把系统调用看成是一种不能再化简的操作(类似于原子操作,但是不同概念),有人把它比作一个汉字的一个“笔画”,而一个“汉字”就代表一个上层应用,我觉得这个比喻非常贴切。因此,有时候如果要实现一个完整的汉字(给某个变量分配内存空间),就必须调用很多的系统调用。如果从实现者(程序员)的角度来看,这势必会加重程序员的负担,良好的程序设计方法是:重视上层的业务逻辑操作,而尽可能避免底层复杂的实现细节。
库函数正是为了将程序员从复杂的细节中解脱出来而提出的一种有效方法。它实现对系统调用的封装,将简单的业务逻辑接口呈现给用户,方便用户调用,从这个角度上看,库函数就像是组成汉字的“偏旁”。这样的一种组成方式极大增强了程序设计的灵活性,对于简单的操作,我们可以直接调用系统调用来访问资源,如“人”,对于复杂操作,我们借助于库函数来实现,如“仁”。显然,这样的库函数依据不同的标准也可以有不同的实现版本,如ISO C 标准库,POSIX 标准库等。
Shell 是一个特殊的应用程序,俗称命令行,本质上是一个命令解释器,它下通系统调用,上通各种应用,通常充当着一种“胶水”的角色,来连接各个小功能程序,让不同程序能够以一个清晰的接口协同工作,从而增强各个程序的功能。
同时,Shell 是可编程的,它可以执行符合 Shell 语法的文本,这样的文本称为 Shell 脚本,通常短短的几行 Shell 脚本就可以实现一个非常大的功能,原因就是这些 Shell 语句通常都对系统调用做了一层封装。为了方便用户和系统交互,一般,一个 Shell 对应一个终端,终端是一个硬件设备,呈现给用户的是一个图形化窗口。我们可以通过这个窗口输入或者输出文本。这个文本直接传递给 Shell 进行分析解释,然后执行。
总结一下,用户态的应用程序可以通过三种方式来访问内核态的资源:
下图是对上图的一个细分结构,从这个图上可以更进一步对内核所做的事有一个“全景式”的印象。主要表现为:向下控制硬件资源,向内管理操作系统资源:包括进程的调度和管理、内存的管理、文件系统的管理、设备驱动程序的管理以及网络资源的管理,向上则向应用程序提供系统调用的接口。
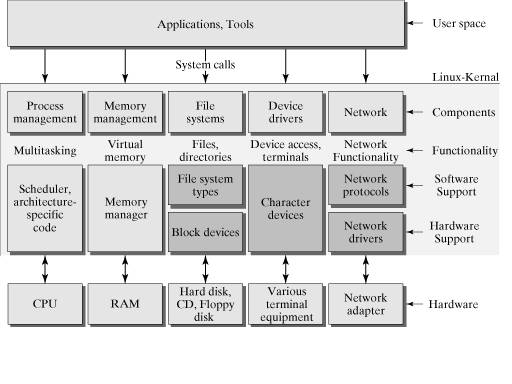
从整体上来看,整个操作系统分为两层:用户态和内核态,这种分层的架构极大地提高了资源管理的可扩展性和灵活性,而且方便用户对资源的调用和集中式的管理,带来一定的安全性。
因为操作系统的资源是有限的,如果访问资源的操作过多,必然会消耗过多的资源,而且如果不对这些操作加以区分,很可能造成资源访问的冲突。
所以,为了减少有限资源的访问和使用冲突,Unix/Linux 的设计哲学之一就是:对不同的操作赋予不同的执行等级,就是所谓特权的概念。简单说就是有多大能力做多大的事,与系统相关的一些特别关键的操作必须由最高特权的程序来完成。Intel 的 X86 架构的 CPU 提供了 0 到 3 四个特权级,数字越小,特权越高。
Linux 操作系统中主要采用了 0 和 3 两个特权级,分别对应的就是内核态和用户态。运行于用户态的进程可以执行的操作和访问的资源都会受到极大的限制,而运行在内核态的进程则可以执行任何操作并且在资源的使用上没有限制。
很多程序开始时运行于用户态,但在执行的过程中,一些操作需要在内核权限下才能执行,这就涉及到一个从用户态切换到内核态的过程。比如C函数库中的内存分配函数 malloc(),它具体是使用 sbrk() 系统调用来分配内存,当malloc() 调用 sbrk() 的时候就涉及一次从用户态到内核态的切换,类似的函数还有 printf(),调用的是 wirte() 系统调用来输出字符串,等等。
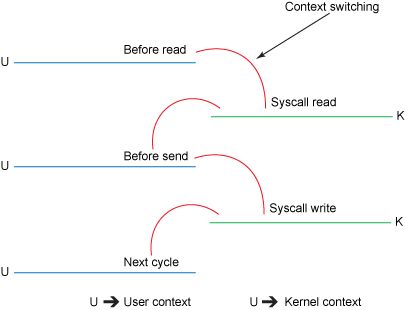
那到底在什么情况下会发生从用户态到内核态的切换,一般存在以下三种情况:
注意: 系统调用的本质其实也是中断,相对于外围设备的硬中断,这种中断称为软中断,这是操作系统为用户特别开放的一种中断,如 Linux int 80h 中断。所以,从触发方式和效果上来看,这三种切换方式是完全一样的,都相当于是执行了一个中断响应的过程。但是从触发的对象来看,系统调用是进程主动请求切换的,而异常和硬中断则是被动的。
本文仅是从宏观的角度去理解 Linux 用户态和内核态的设计,并没有去深究它们的具体实现方式。从实现上来看,必须要考虑到的一点我想就是性能问题,因为用户态和内核态之间的切换会消耗大量资源。
PS:文章未经我允许,不得转载,否则后果自负。
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。

文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
这是 Linux 性能分析系列的第五篇,前四篇在这里:
一文掌握 Linux 性能分析之 CPU 篇
一文掌握 Linux 性能分析之内存篇
一文掌握 Linux 性能分析之 IO 篇
一文掌握 Linux 性能分析之网络篇
在上篇中,我们已经介绍了几个 Linux 网络方向的性能分析工具,本文再补充几个。总结下来,余下的工具包括但不限于以下几个:
由于篇幅有限,本文会先介绍前面两个,其他工具留作后面介绍,大家可以持续关注。
sar 是一个系统历史数据统计工具。统计的信息非常全,包括 CPU、内存、磁盘 I/O、网络、进程、系统调用等等信息,是一个集大成的工具,非常强大。在 Linux 系统上 sar --help 一下,可以看到它的完整用法。
在平时使用中,我们常常用来分析网络状况,其他几项的通常有更好的工具来分析。所以,本文会重点介绍 sar 在网络方面的分析手法。
Linux 系统用以下几个选项提供网络统计信息:
我们来看几个示例:
(1)每秒打印 TCP 的统计信息:
sar -n TCP 1
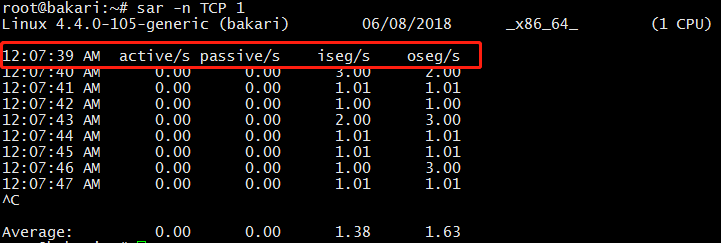
几个参数了解一下:
(2)每秒打印感兴趣的网卡的统计信息:
sar -n DEV 1 | awk 'NR == 3 || $3 == "eth0"'

几个参数了解一下:
(3)错误包和丢包情况分析:
sar -n EDEV 1

几个参数了解一下:
当发现接口传输数据包有问题时,查看以上参数能够让我们快速判断具体是出的什么问题。
OK,这个工具就介绍到这里,以上只是抛砖引玉,更多技巧还需要大家动手去探索,只有动手,才能融会贯通。
traceroute 也是一个排查网络问题的好工具,它能显示数据包到达目标主机所经过的路径(路由器或网关的 IP 地址)。如果发现网络不通,我们可以通过这个命令来进一步判断是主机的问题还是网关的问题。
它通过向源主机和目标主机之间的设备发送一系列的探测数据包(UDP 或者 ICMP)来发现设备的存在,实现上利用了递增每一个包的 TTL 时间,来探测最终的目标主机。比如开始 TTL = 1,当到达第一个网关设备的时候,TTL - 1,当 TTL = 0 导致网关响应一个 ICMP 超时报文,这样,如果没有防火墙拦截的话,源主机就知道网关设备的地址。以此类推,逐步增加 TTL 时间,就可以探测到目标主机之间所经过的路径。
为了防止发送和响应过程出现问题导致丢包,traceroute 默认会发送 3 个探测包,我们可以用 -q x 来改变探测的数量。如果中间设备设置了防火墙限制,会导致源主机收不到响应包,就会显示 * 号。如下是 traceroute baidu 的结果:
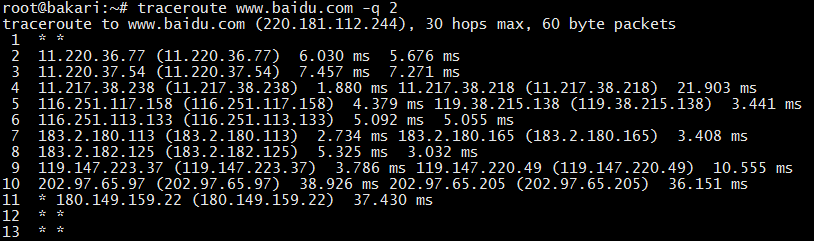
每一行默认会显示设备名称(IP 地址)和对应的响应时间。发送多少个探测包,就显示多少个。如果只想显示 IP 地址可以用 -n 参数,这个参数可以避免 DNS 域名解析,加快响应时间。
和这个工具类似的还有一个工具叫 pathchar,但平时用的不多,我就不介绍了。
以上就是两个工具的简单介绍,工具虽然简单,但只要能解决问题,就是好工具。当然,性能分析不仅仅依靠工具就能解决的,更多需要我们多思考、多动手、多总结,逐步培养自己的系统能力,才能融会贯通。
PS:文章未经我允许,不得转载,否则后果自负。
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。
文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
这是 Linux 性能分析系列的第四篇。
比较宽泛地讲,网络方向的性能分析既包括主机测的网络配置查看、监控,又包括网络链路上的包转发时延、吞吐量、带宽等指标分析。包括但不限于以下分析工具:
本文先来看前面 7 个。
ping 发送 ICMP echo 数据包来探测网络的连通性,除了能直观地看出网络的连通状况外,还能获得本次连接的往返时间(RTT 时间),丢包情况,以及访问的域名所对应的 IP 地址(使用 DNS 域名解析),比如:
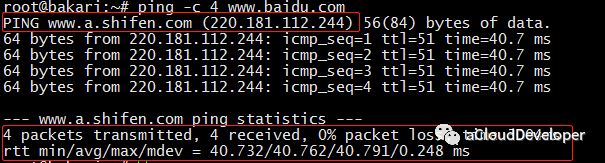
我们 ping baidu.com,-c参数指定发包数。可以看到,解析到了 baidu 的一台服务器 IP 地址为 220.181.112.244。RTT 时间的最小、平均、最大和算术平均差分别是 40.732ms、40.762ms、40.791ms 和 0.248。
ifconfig 命令被用于配置和显示 Linux 内核中网络接口的统计信息。通过这些统计信息,我们也能够进行一定的网络性能调优。
1)ifconfig 显示网络接口配置信息
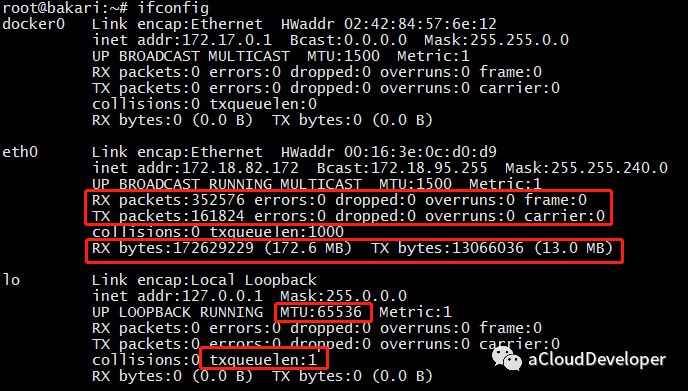
其中,RX/TX packets 是对接收/发送数据包的情况统计,包括错误的包,丢掉多少包等。RX/TX bytes 是接收/发送数据字节数统计。其余还有很多参数,就不一一述说了,性能调优时可以重点关注 MTU(最大传输单元) 和 txqueuelen(发送队列长度),比如可以用下面的命令来对这两个参数进行微调:1
2ifconfig eth0 txqueuelen 2000
ifconfig eth0 mtu 1500
2)网络接口地址配置
ifconfig 还常用来配置网口的地址,比如:
为网卡配置和删除 IPv6 地址:1
2ifconfig eth0 add 33ffe:3240:800:1005::2/64 #为网卡eth0配置IPv6地址
ifconfig eth0 del 33ffe:3240:800:1005::2/64 #为网卡eth0删除IPv6地址
修改MAC地址:1
ifconfig eth0 hw ether 00:AA:BB:CC:dd:EE
配置IP地址:1
2
3ifconfig eth0 192.168.2.10
ifconfig eth0 192.168.2.10 netmask 255.255.255.0
ifconfig eth0 192.168.2.10 netmask 255.255.255.0 broadcast 192.168.2.255
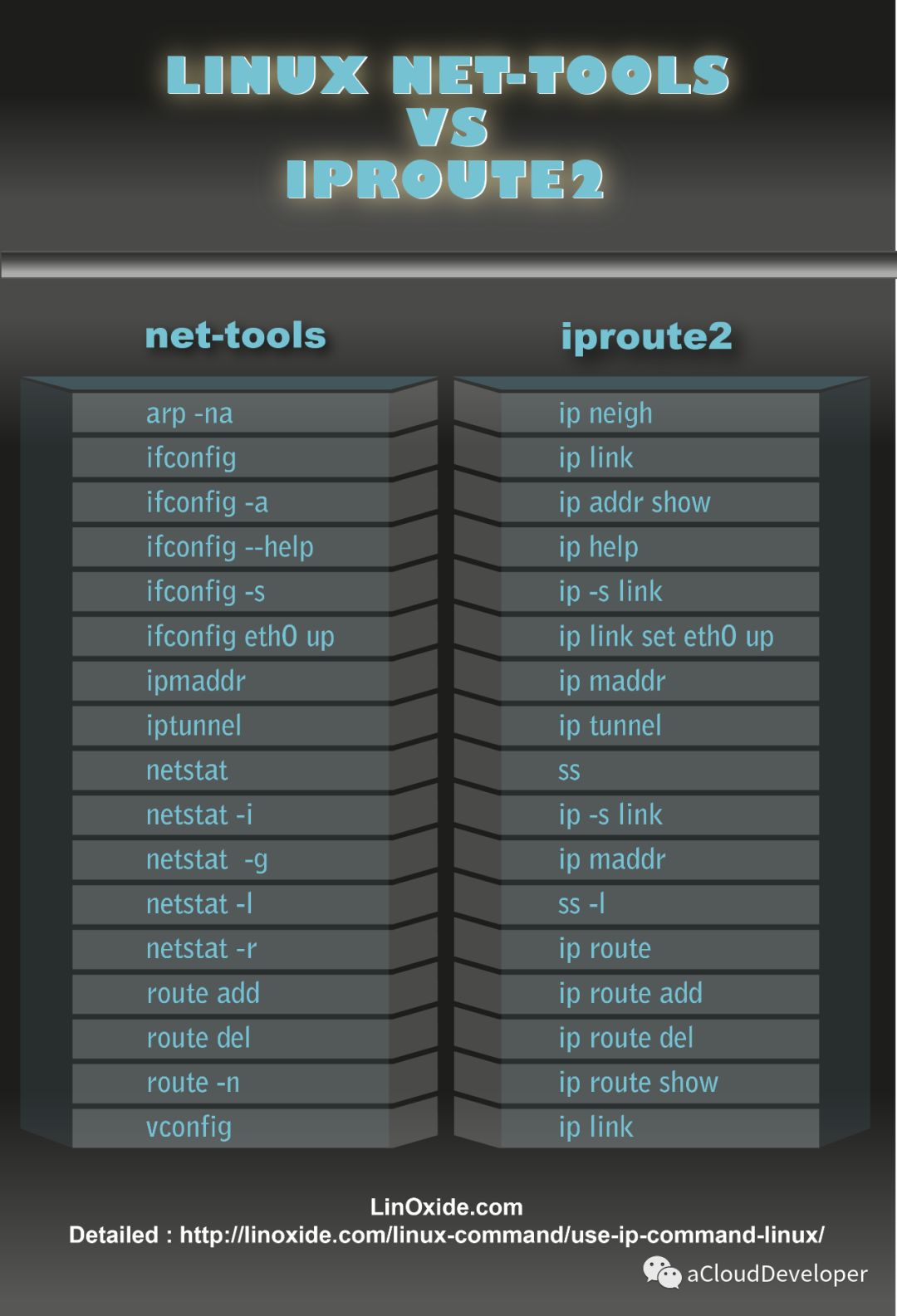
ip 命令用来显示或设置 Linux 主机的网络接口、路由、网络设备、策略路由和隧道等信息,是 Linux 下功能强大的网络配置工具,旨在替代 ifconfig 命令,如下显示 IP 命令的强大之处,功能涵盖到 ifconfig、netstat、route 三个命令。
netstat 可以查看整个 Linux 系统关于网络的情况,是一个集多钟网络工具于一身的组合工具。
常用的选项包括以下几个:
各参数组合使用实例如下:
1)netstat 默认显示连接的套接字数据
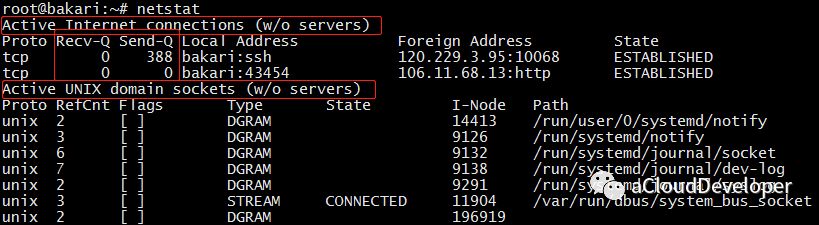
整体上来看,输出结果包括两个部分:
2)netstat -i 显示网络接口信息

接口信息包括网络接口名称(Iface)、MTU,以及一系列接收(RX-)和传输(TX-)的指标。其中 OK 表示传输成功的包,ERR 是错误包,DRP 是丢包,OVR 是超限包。
这些参数有助于我们对网络收包情况进行分析,从而判断瓶颈所在。
3)netstat -s 显示所有网络协议栈的信息
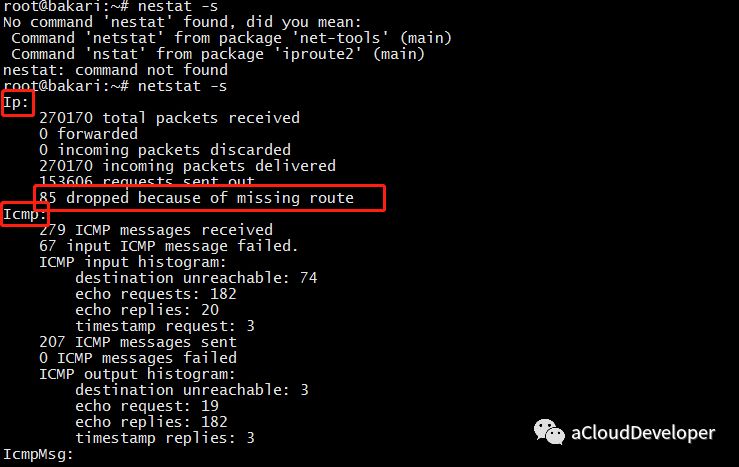
可以看到,这条命令能够显示每个协议详细的信息,这有助于我们针对协议栈进行更细粒度的分析。
4)netstat -r 显示路由表信息
这条命令能够看到主机路由表的一个情况。当然查路由我们也可以用 ip route 和 route 命令,这个命令显示的信息会更详细一些。
ifstat 主要用来监测主机网口的网络流量,常用的选项包括:
比如,通过以下命令统计主机所有网口某一段时间内的流量数据:
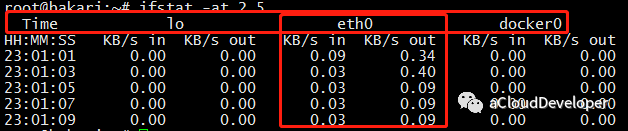
可以看出,分别统计了三个网口的流量数据,前面输出的时间戳,有助于我们统计一段时间内各网口总的输入、输出流量。
netcat,简称 nc,命令简单,但功能强大,在排查网络故障时非常有用,因此它也在众多网络工具中有着“瑞士军刀”的美誉。
它主要被用来构建网络连接。可以以客户端和服务端的方式运行,当以服务端方式运行时,它负责监听某个端口并接受客户端的连接,因此可以用它来调试客户端程序;当以客户端方式运行时,它负责向服务端发起连接并收发数据,因此也可以用它来调试服务端程序,此时它有点像 Telnet 程序。
常用的选项包括以下几种:
下面举一个简单的例子,使用 nc 命令发送消息:
首先,启动服务端,用 nc -l 0.0.0.0 12345 监听端口 12345 上的所有连接。

然后,启动客户端,用 nc -p 1234 127.0.0.1 12345 使用 1234 端口连接服务器 127.0.0.1::12345。

接着就可以在两端互发数据了。这里只是抛砖引玉,更多例子大家可以多实践。
最后是 tcpdump,强大的网络抓包工具。虽然有 wireshark 这样更易使用的图形化抓包工具,但 tcpdump 仍然是网络排错的必备利器。
tcpdump 选项很多,我就不一一列举了,大家可以看文章末尾的引用来进一步了解。这里列举几种 tcpdump 常用的用法。
1)捕获某主机的数据包
比如想要捕获主机 200.200.200.100 上所有收到和发出的所有数据包,使用:1
tcpdump host 200.200.200.100
2)捕获多个主机的数据包
比如要捕获主机 200.200.200.1 和主机 200.200.200.2 或 200.200.200.3 的通信,使用:1
tcpdump host 200.200.200.1 and \(200.200.200.2 or \)
同样要捕获主机 200.200.200.1 除了和主机 200.200.200.2 之外所有主机通信的 IP 包。使用:1
tcpdump ip host 200.200.200.1 and ! 200.200.200.2
3)捕获某主机接收或发出的某种协议类型的包
比如要捕获主机 200.200.200.1 接收或发出的 Telnet 包,使用:1
tcpdump tcp port 23 host 200.200.200.1
4)捕获某端口相关的数据包
比如捕获在端口 6666 上通过的包,使用:1
tcpdump port 6666
5)捕获某网口的数据包
比如捕获在网口 eth0 上通过的包,使用:1
tcpdump -i eth0
下面还是举个例子,抓取 TCP 三次握手的包:
首先,用 nc 启动一个服务端,监听端口 12345 上客户端的连接:1
nc -v -l 0.0.0.0 12345
接着,启动 tcpdump 监听端口 12345 上通过的包:1
tcpdump -i any 'port 12345' -XX -nn -vv -S
然后,再用 nc 启动客户端,连接服务端:1
nc -v 127.0.0.1 12345
最后,我们看到 tcpdump 抓到包如下:
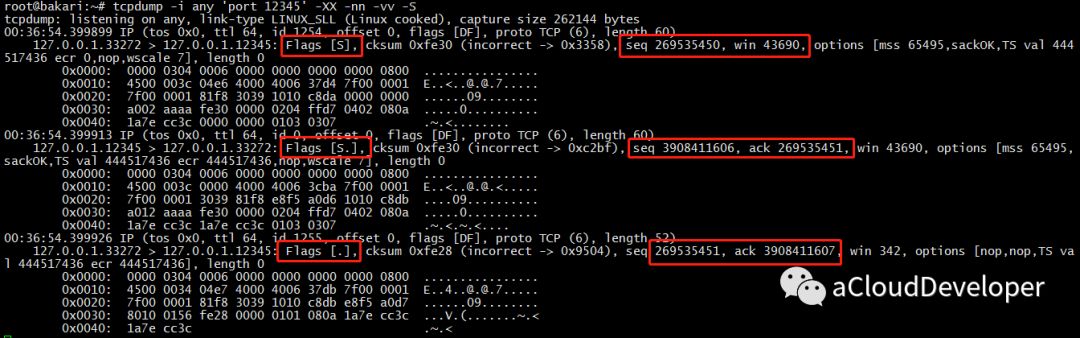
怎么分析是 TCP 的三次握手,就当做小作业留给大家吧,其实看图就已经很明显了。
本文总结了几种初级的网络工具,一般的网络性能分析,通过组合以上几种工具,基本都能应付,但对于复杂的问题,以上工具可能就无能为力了。更多高阶的工具将在下文送上,敬请期待。
Reference:
PS:文章未经我允许,不得转载,否则后果自负。
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。
文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
这是 Linux 性能分析系列的第三篇。
IO 和 存储密切相关,存储可以概括为磁盘,内存,缓存,三者读写的性能差距非常大,磁盘读写是毫秒级的(一般 0.1-10ms),内存读写是微妙级的(一般 0.1-10us),cache 是纳秒级的(一般 1-10ns)。但这也是牺牲其他特性为代价的,速度快的,价格越贵,容量也越小。
IO 性能这块,我们更多关注的是读写磁盘的性能。首先,先了解下磁盘的基本信息。
查看磁盘信息,包括磁盘容量,扇区大小,IO 大小等信息,常用 fdisk -l查看:
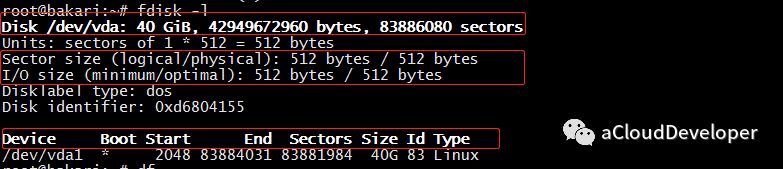
可以看到 /dev/ 下有一个 40G 的硬盘,一共 8K 多万个扇区,每个扇区 512字节,IO 大小也是 512 字节。
查看磁盘使用情况,通常看磁盘使用率:

主要分析磁盘的读写效率(IOPS:每秒读写的次数;吞吐量:每秒读写的数据量),IO 繁忙程度,及 IO 访问对 CPU 的消耗等性能指标。
第一个较为常用的还是这个万能的 vmstat:
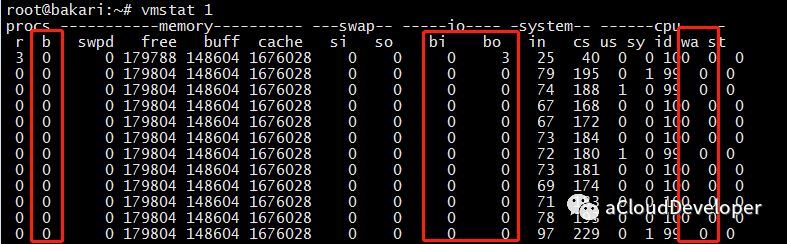
对于 IO,我们常关注三个部分:
一般这几个值偏大,都意味着系统 IO 的消耗较大,对于读请求较大的服务器,b、bo、wa 的值偏大,而写请求较大的服务器,b、bi、wa 的值偏大。
vmstat 虽然万能,但是它分析的东西有限,iostat 是专业分析 IO 性能的工具,可以方便查看 CPU、网卡、tty 设备、磁盘、CD-ROM 等等设备的信息,非常强大,总结下来,共有以下几种用法:
1)iostat -c 查看部分 CPU 使用情况:

这里显示的是多个 CPU 的平均值,每个字段的含义我就不多解释了,我一般会重点关注 %iowait 和 %idle,分别表示 CPU 等待 IO 完成时间的百分比和 CPU 空闲时间百分比。
如果 %iowait 较高,则表明磁盘存在 IO 瓶颈,如果 %idle 较高,则 CPU 比较空闲,如果两个值都比较高,则有可能 CPU 在等待分配内存,瓶颈在内存,此时应该加大内存,如果 %idle 较低,则此时瓶颈在 CPU,应该增加 CPU 资源。
2)iostat -d 查看磁盘使用情况,主要是显示 IOPS 和吞吐量信息(-k : 以 KB 为单位显示,-m:以 M 为单位显示):

其中,几个参数分别解释如下:
3)iostat -x 查看磁盘详细信息:

其中,几个参数解释如下;
以上这些参数太多了,我们并不需要每个都关注,可以重点关注两个:
a. %util:衡量 IO 的繁忙程度
这个值越大,说明产生的 IO 请求较多,IO 压力较大,我们可以结合 %idle 参数来看,如果 %idle < 70% 就说明 IO 比较繁忙了。也可以结合 vmstat 的 b 参数(等待 IO 的进程数)和 wa 参数(IO 等待所占 CPU 时间百分比)来看,如果 wa > 30% 也说明 IO 较为繁忙。
b. await:衡量 IO 的响应速度
通俗理解,await 就像我们去医院看病排队等待的时间,这个值和医生的服务速度(svctm)和你前面排队的人数(avgqu-size)有关。如果 svctm 和 await 接近,说明磁盘 IO 响应时间较快,排队较少,如果 await 远大于 svctm,说明此时队列太长,响应较慢,这时可以考虑换性能更好的磁盘或升级 CPU。
4)iostat 1 2 默认显示 cpu 和 吞吐量信息,1 定时 1s 显示,2 显示 2 条信息
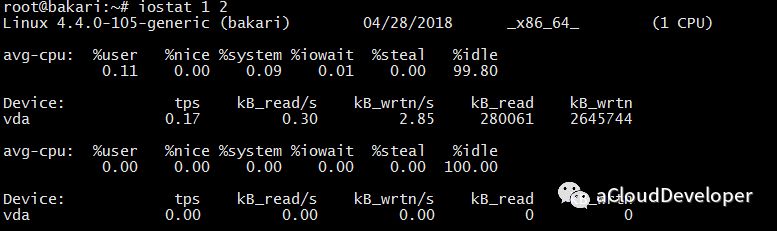
有了以上两个命令,基本上能对磁盘 IO 的信息有个全方位的了解了。但如果要确定具体哪个进程的 IO 开销较大,这就得借助另外的工具了。
这个命令类似 top,可以显示每个进程的 IO 情况,有了这个命令,就可以定位具体哪个进程的 IO 开销比较大了。
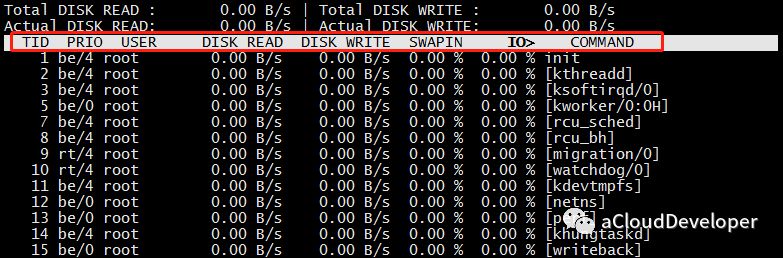
OK,最后还是总结下,fdisk -l 和 df 查看磁盘基本信息,iostat -d 查看磁盘 IOPS 和吞吐量,iostat -x 结合 vmstat 查看磁盘的繁忙程度和处理效率。
下文我们将探讨网络方面的的性能分析问题。
Reference:
1.linux 性能分析:
http://linuxtools-rst.readthedocs.io/zh_CN/latest/tool/iostat.html
PS:文章未经我允许,不得转载,否则后果自负。
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。
文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
同样在分析内存之前,我们得知到怎么查看系统内存信息,有以下几种方法。
这个文件记录着比较详细的内存配置信息,使用 cat /proc/meminfo 查看。
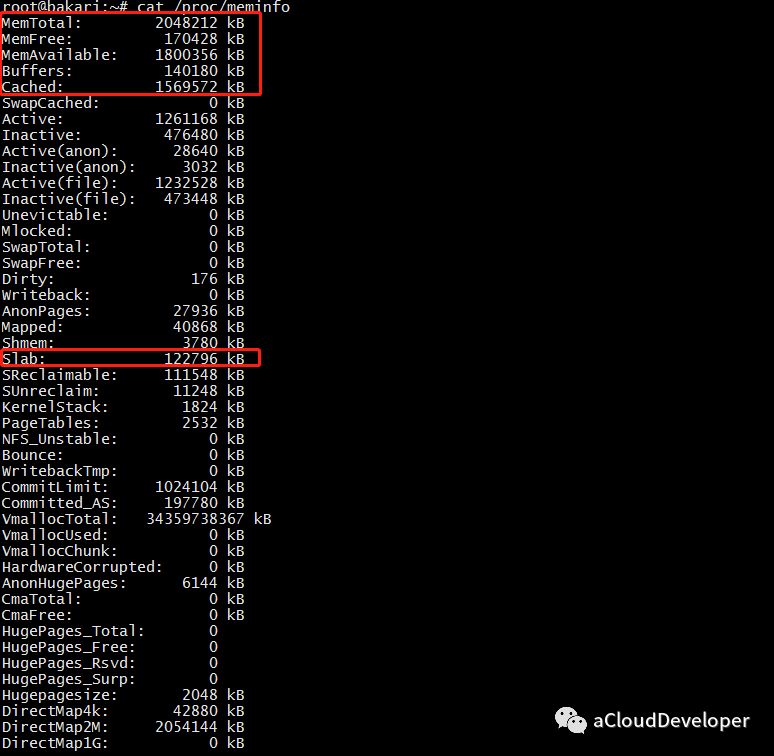
我们比较关心的是下面几个字段:
上面信息没有 MemUsed 的值,虽然可以用现有的值大致估算出来,但是我们想一步到位,就用下面的 free 命令。
这个命令估计用的人就多了(我一般都是用这个命令)。

这里存在一个计算公式:
MemTotal = used + free + buff/cache(单位 K)
几个字段和上面 /proc/meminfo 的字段是对应的。还有个 shared 字段,这个是多进程的共享内存空间,不常用。
我们注意到 free 很小,buff/cache 却很大,这是 Linux 的内存设计决定的,Linux 的想法是内存闲着反正也是闲着,不如拿出来做系统缓存和缓冲区,提高数据读写的速率。但是当系统内存不足时,buff/cache 会让出部分来,非常灵活的操作。
要看比较直观的值,可以加 -h 参数:

同样可以使用这个命令,对于内存,可以使用 dmidecode -t memory 查看:
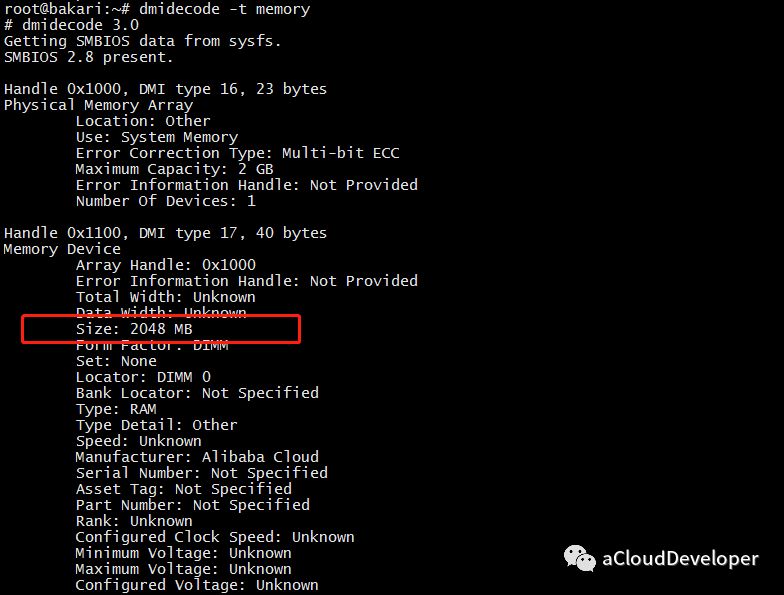
这个命令也是非常常用了。但对于内存,显示信息有限。它更多是用于进行系统全局分析和 CPU 分析。详细可以看 CPU 分析一文。

最常用的两个命令 ps 和 top,虽然很简单的两个命令,但还是有不少学问的。
top 命令运行时默认是按照 CPU 利用率进行排序的,如果要按照内存排序,该怎么操作呢?两种方法,一种直接按 “M”(相应的按 “P” 是 CPU),另外一种是在键入 top 之后,按下 “F”,然后选择要排序的字段,再按下 “s” 确认即可。
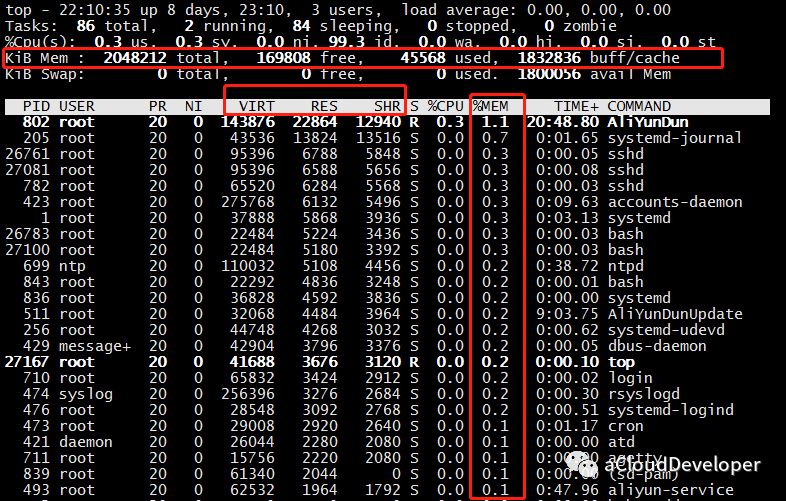
可以看到,我按照 “%MEM” 排序的结果。这个结果对于查看系统占用内存较多的哪些进程是比较有用的。
然后这里我们会重点关注几个地方,上面横排区,和前面几个命令一样可以查看系统内存信息,中间标注的横条部分,和内存相关的有三个字段:VIRT、RES、SHR。
ps 同样可以查看进程占用内存情况,一般常用来查看 Top n 进程占用内存情况,如:
ps aux --sort=rss | head -n,表示按 rss 排序,取 Top n。
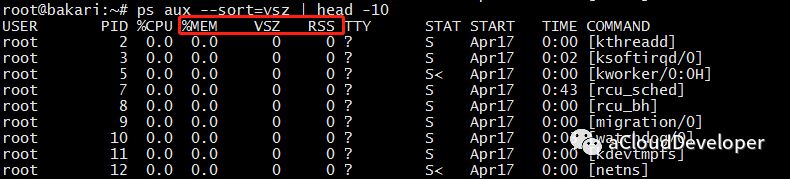
这里也关注三个字段:
这个命令用于查看进程的内存映像信息,能够查看进程在哪些地方用了多少内存。常用 pmap -x pid 来查看。
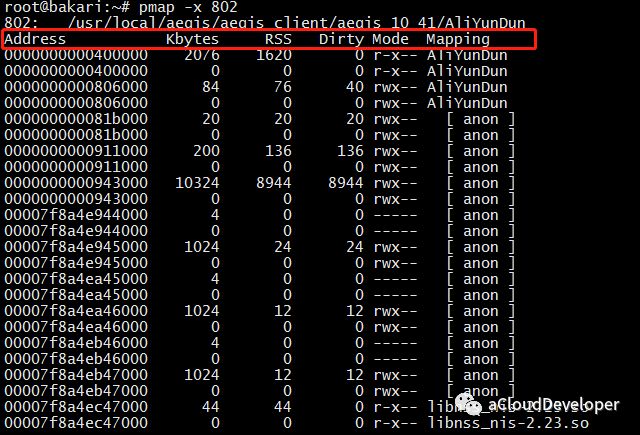
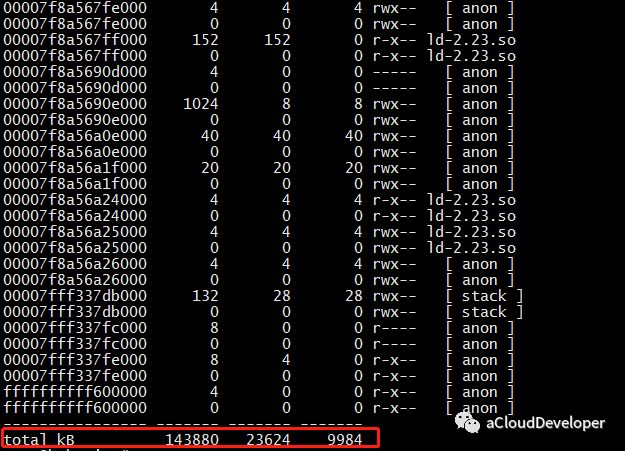
可以看到该进程内存被哪些库、哪些文件所占用,据此我们定位程序对内存的使用。
几个字段介绍一下:
while true; do pmap -x pid | tail -1; sleep 1; doneOK,以上工具都是 Linux 自带的,当然还有很多高阶的工具,比如 atop、memstat 等等,对于内存泄漏有一个比较常用的检测工具 Valgrind,这些等之后再找时间跟大家分享了。
通过以上手段,我们基本上就能定位内存问题所在了,究竟是内存太小,还是进程占用内存太多,有哪些进程占用较多,这些进程又究竟有哪些地方占用较多,这些问题通过以上方法都能解决。
最后简单总结下,以上不少工具可能有人会犯选择困难症了。对于我来说,查看系统内存用 free -h,分析进程内存占用用 ps 或者 top(首选 ps),深入分析选择 pmap,就酱。
Reference:
1.Linux下查看内存使用情况的多种方法:
http://stor.51cto.com/art/201804/570236.htm
PS:文章未经我允许,不得转载,否则后果自负。
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。