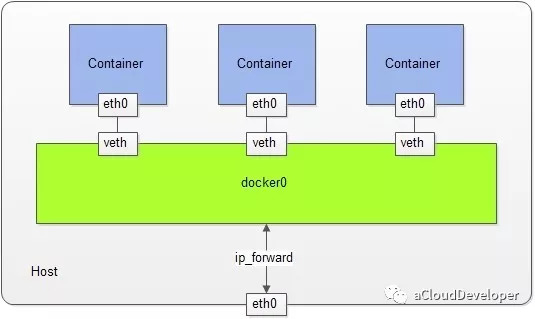
文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
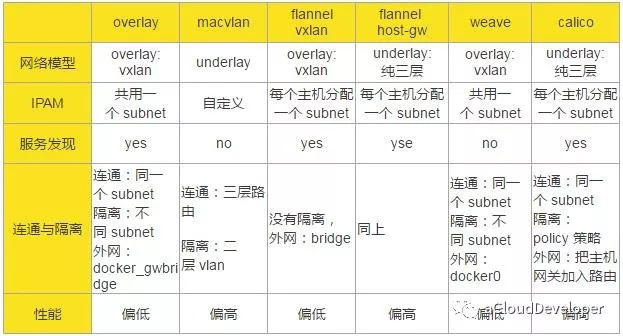
上篇文章介绍了容器网络的单主机网络,本文将进一步介绍多主机网络,也就是跨主机的网络。总结下来,多主机网络解决方案包括但不限于以下几种:overlay、macvlan、flannel、weave、cacico 等,下面将分别一一介绍这几种网络,
PS:本文仅从原理上对几种网络进行简单的对比总结,不涉及太多的细节。
1 overlay
俗称隧道网络,它是基于 VxLAN 协议来将二层数据包封装到 UDP 中进行传输的,目的是扩展二层网段,因为 VLAN 使用 12bit 标记 VLAN ID,最多支持 4094 个 VLAN,这对于大型云网络会成为瓶颈,而 VxLAN ID 使用 24bit 来标记,支持多达 16777216 个二层网段,所以 VxLAN 是扩展了 VLAN,也叫做大二层网络。
overlay 网络需要一个全局的“上帝”来记录它网络中的信息,比如主机地址,子网等,这个上帝在 Docker 中是由服务发现协议来完成的,服务发现本质上是一个 key-value 数据库,要使用它,首先需要向它告知(注册)一些必要的信息(如网络中需要通信的主机),然后它就会自动去收集、同步网络的信息,同时,还会维护一个 IP 地址池,分配给主机中的容器使用。Docker 中比较有名的服务发现有 Consul、Etcd 和 ZooKeeper。overlay 网络常用 Consul。
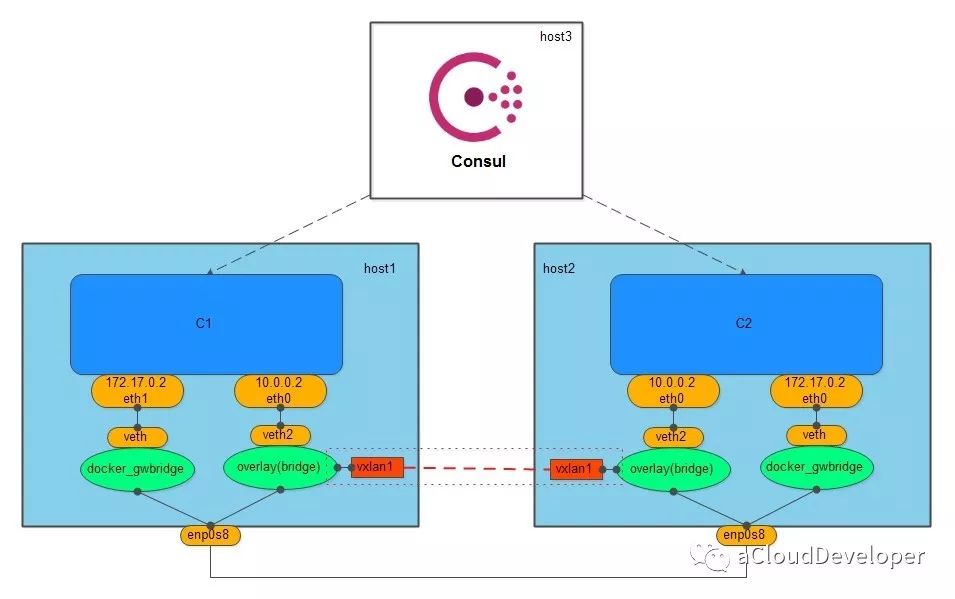
创建 overlay 网络会创建一个 Linux bridge br0,br0 会创建两个接口,一个 veth2 作为与容器的虚拟网卡相连的 veth pair,另一个 vxlan1 负责与其他 host 建立 VxLAN 隧道,跨主机的容器就通过这个隧道来进行通信。
为了保证 overlay 网络中的容器与外网互通,Docker 会创建另一个 Linux bridge docker_gwbridge,同样,该 bridge 也存在一对 veth pair,要与外围通信的容器可以通过这对 veth pair 到达 docker_gwbridge,进而通过主机 NAT 访问外网。
2 macvlan
macvlan 就如它的名字一样,是一种网卡虚拟化技术,它能够将一个物理网卡虚拟出多个接口,每个接口都可以配置 MAC 地址,同样每个接口也可以配自己的 IP,每个接口就像交换机的端口一样,可以为它划分 VLAN。
macvlan 的做法其实就是将这些虚拟出来的接口与 Docker 容器直连来达到通信的目的。一个 macvlan 网络对应一个接口,不同的 macvlan 网络分配不同的子网,因此,相同的 macvlan 之间可以互相通信,不同的 macvlan 网络之间在二层上不能通信,需要借助三层的路由器才能完成通信,如下,显示的就是两个不同的 macvlan 网络之间的通信流程。
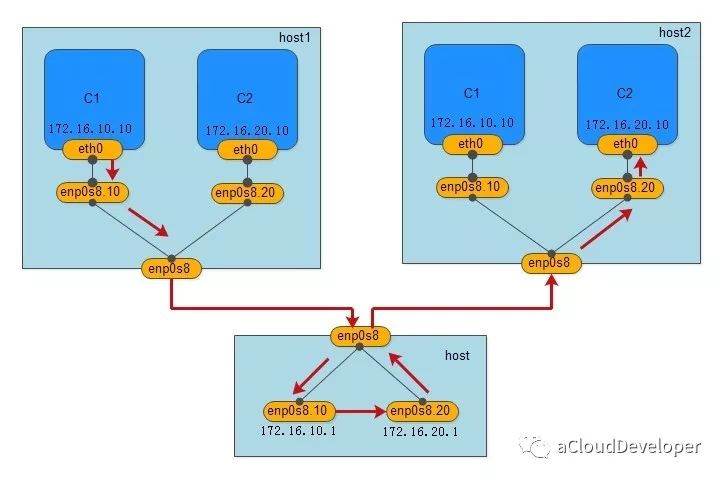
我们用一个 Linux 主机,通过配置其路由表和 iptables,将其配成一个路由器(当然是虚拟的),就可以完成不同 macvlan 网络之间的数据交换,当然用物理路由器也是没毛病的。
3 flannel
flannel 网络也需要借助一个全局的上帝来同步网络信息,一般使用的是 etcd。
flannel 网络不会创建新的 bridge,而是用默认的 docker0,但创建 flannel 网络会在主机上创建一个虚拟网卡,挂在 docker0 上,用于跨主机通信。
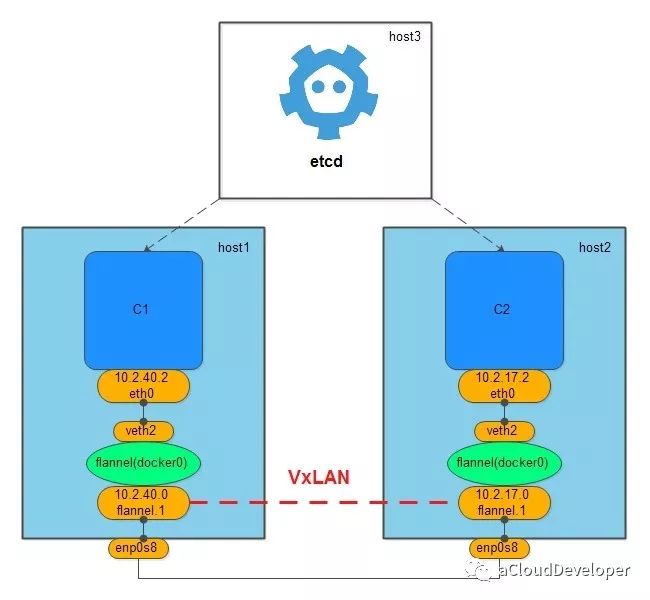
组件方式让 flannel 多了几分灵活性,它可以使用二层的 VxLAN 隧道来封装数据包完成跨主机通信,也可以使用纯三层的方案来通信,比如 host-gw,只需修改一个配置文件就可以完成转化。
4 weave
weave 网络没有借助服务发现协议,也没有 macvlan 那样的虚拟化技术,只需要在不同主机上启动 weave 组件就可以完成通信。
创建 weave 网络会创建两个网桥,一个是 Linux bridge weave,一个是 datapath,也就是 OVS,weave 负责将容器加入 weave 网络中,OVS 负责将跨主机通信的数据包封装成 VxLAN 包进行隧道传输。
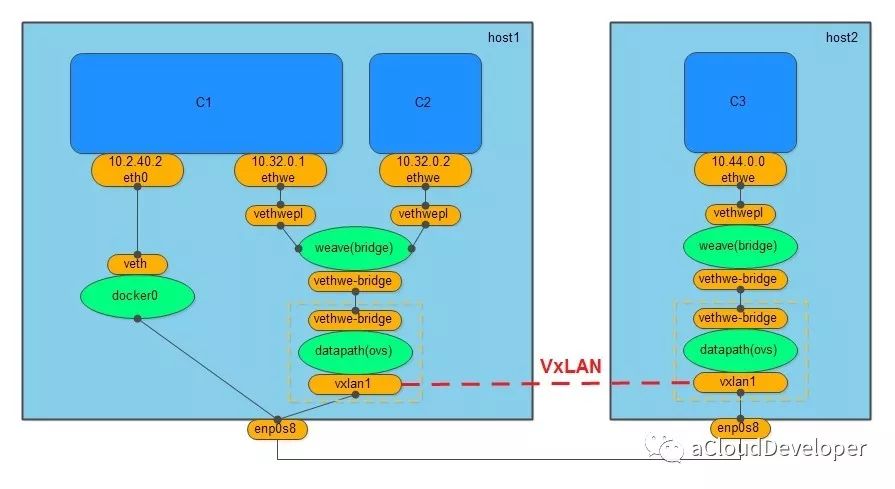
同样,weave 网络也不支持与外网通信,Docker 提供 docker0 来满足这个需求。
weave 网络通过组件化的方式使得网络分层比较清晰,两个网桥的分工也比较明确,一个用于跨主机通信,相当于一个路由器,一个负责将本地网络加入 weave 网络。
5 calico
calico 是一个纯三层的网络,它没有创建任何的网桥,它之所以能完成跨主机的通信,是因为它记住 etcd 将网络中各网段的路由信息写进了主机中,然后创建的一对的 veth pair,一块留在容器的 network namespace 中,一块成了主机中的虚拟网卡,加入到主机路由表中,从而打通不同主机中的容器通信。
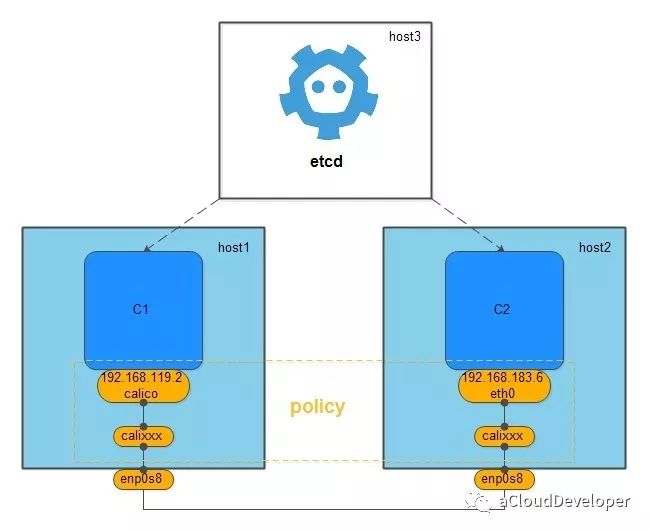
calico 相较其他几个网络方案最大优点是它提供 policy 机制,用户可以根据自己的需求自定义 policy,一个 policy 可能对应一条 ACL,用于控制进出容器的数据包,比如我们建立了多个 calico 网络,想控制其中几个网络可以互通,其余不能互通,就可以修改 policy 的配置文件来满足要求,这种方式大大增加了网络连通和隔离的灵活性。
6 总结
1、除了以上的几种方案,跨主机容器网络方案还有很多,比如:Romana,Contiv 等,本文就不作过多展开了,大家感兴趣可以查阅相关资料了解。
2、跨主机的容器网络通常要为不同主机的容器维护一个 IP 池,所以大多方案需要借助第三方的服务发现方案。
3、跨主机容器网络按传输方式可以分为纯二层网络,隧道网络(大二层网络),以及纯三层网络。
PS:文章未经我允许,不得转载,否则后果自负。
–END–
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。