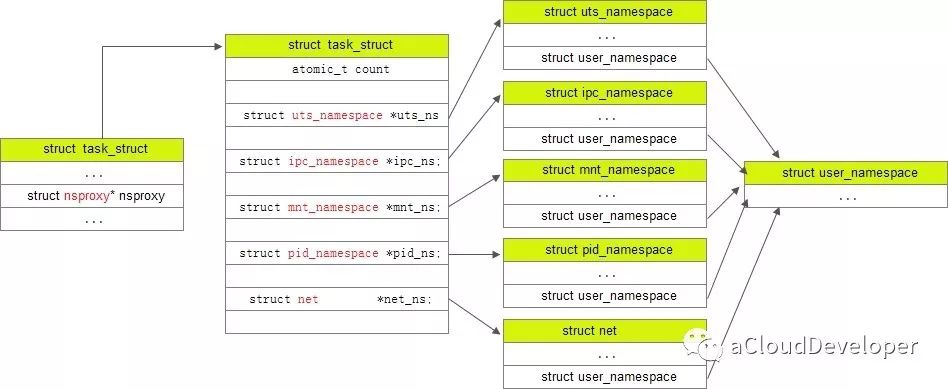
/* * A structure to contain pointers to all per-process * namespaces - fs (mount), uts, network, sysvipc, etc. * * 'count' is the number of tasks holding a reference. * The count for each namespace, then, will be the number * of nsproxies pointing to it, not the number of tasks. * * The nsproxy is shared by tasks which share all namespaces. * As soon as a single namespace is cloned or unshared, the * nsproxy is copied. */ struct nsproxy { atomic_t count; struct uts_namespace *uts_ns; struct ipc_namespace *ipc_ns; struct mnt_namespace *mnt_ns; struct pid_namespace *pid_ns; struct net *net_ns; }; extern struct nsproxy init_nsproxy;
/* * INIT_TASK is used to set up the first task table, touch at * your own risk!. Base=0, limit=0x1fffff (=2MB) */ #define INIT_TASK(tsk) \ { ...... .nsproxy = &init_nsproxy, ...... }
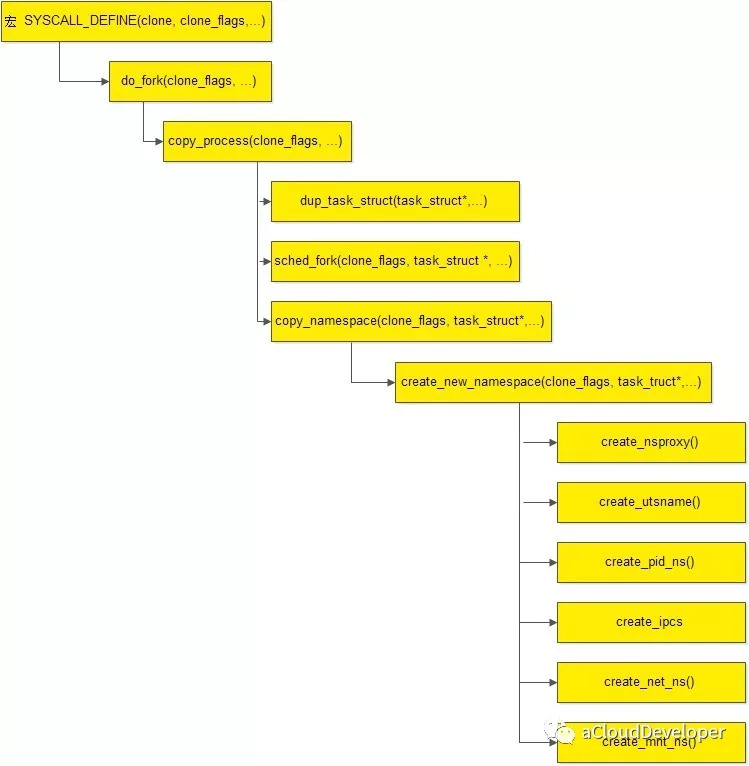
/* * Ok, this is the main fork-routine. * * It copies the process, and if successful kick-starts * it and waits for it to finish using the VM if required. */ long do_fork(unsigned long clone_flags, unsigned long stack_start, unsigned long stack_size, int __user *parent_tidptr, int __user *child_tidptr) { // 创建进程描述符指针 struct task_struct *p; int trace = 0; long nr;
/* * Determine whether and which event to report to ptracer. When * called from kernel_thread or CLONE_UNTRACED is explicitly * requested, no event is reported; otherwise, report if the event * for the type of forking is enabled. */ if (!(clone_flags & CLONE_UNTRACED)) { if (clone_flags & CLONE_VFORK) trace = PTRACE_EVENT_VFORK; else if ((clone_flags & CSIGNAL) != SIGCHLD) trace = PTRACE_EVENT_CLONE; else trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace))) trace = 0; }
// 复制进程描述符,返回值是 task_struct p = copy_process(clone_flags, stack_start, stack_size, child_tidptr, NULL, trace); /* * Do this prior waking up the new thread - the thread pointer * might get invalid after that point, if the thread exits quickly. */ if (!IS_ERR(p)) { struct completion vfork; struct pid *pid;
trace_sched_process_fork(current, p);
// 得到新进程描述符的 pid pid = get_task_pid(p, PIDTYPE_PID); nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID) put_user(nr, parent_tidptr);
static struct task_struct *copy_process(unsigned long clone_flags, unsigned long stack_start, unsigned long stack_size, int __user *child_tidptr, struct pid *pid, int trace) { int retval; // 创建进程描述符指针 struct task_struct *p;
if ((clone_flags & (CLONE_NEWUSER|CLONE_FS)) == (CLONE_NEWUSER|CLONE_FS)) return ERR_PTR(-EINVAL);
/* * Thread groups must share signals as well, and detached threads * can only be started up within the thread group. */ if ((clone_flags & CLONE_THREAD) && !(clone_flags & CLONE_SIGHAND)) return ERR_PTR(-EINVAL);
/* * Shared signal handlers imply shared VM. By way of the above, * thread groups also imply shared VM. Blocking this case allows * for various simplifications in other code. */ if ((clone_flags & CLONE_SIGHAND) && !(clone_flags & CLONE_VM)) return ERR_PTR(-EINVAL);
/* * Siblings of global init remain as zombies on exit since they are * not reaped by their parent (swapper). To solve this and to avoid * multi-rooted process trees, prevent global and container-inits * from creating siblings. */ // 比如CLONE_PARENT时得检查当前signal flags是否为SIGNAL_UNKILLABLE,防止kill init进程。 if ((clone_flags & CLONE_PARENT) && current->signal->flags & SIGNAL_UNKILLABLE) return ERR_PTR(-EINVAL);
/* * If the new process will be in a different pid or user namespace * do not allow it to share a thread group or signal handlers or * parent with the forking task. */ if (clone_flags & CLONE_SIGHAND) { if ((clone_flags & (CLONE_NEWUSER | CLONE_NEWPID)) || (task_active_pid_ns(current) != current->nsproxy->pid_ns_for_children)) return ERR_PTR(-EINVAL); }
retval = security_task_create(clone_flags); if (retval) goto fork_out;
retval = -ENOMEM; // 复制当前的 task_struct p = dup_task_struct(current); if (!p) goto fork_out;
// 检查进程是否超过限制,由 OS 定义 if (atomic_read(&p->real_cred->user->processes) >= task_rlimit(p, RLIMIT_NPROC)) { if (p->real_cred->user != INIT_USER && !capable(CAP_SYS_RESOURCE) && !capable(CAP_SYS_ADMIN)) goto bad_fork_free; } current->flags &= ~PF_NPROC_EXCEEDED;
retval = copy_creds(p, clone_flags); if (retval < 0) goto bad_fork_free;
/* * If multiple threads are within copy_process(), then this check * triggers too late. This doesn't hurt, the check is only there * to stop root fork bombs. */ retval = -EAGAIN; // 检查进程数是否超过 max_threads,由内存大小定义 if (nr_threads >= max_threads) goto bad_fork_cleanup_count;
/* * called from clone. This now handles copy for nsproxy and all * namespaces therein. */ int copy_namespaces(unsigned long flags, struct task_struct *tsk) { struct nsproxy *old_ns = tsk->nsproxy; struct user_namespace *user_ns = task_cred_xxx(tsk, user_ns); struct nsproxy *new_ns;
if (!ns_capable(user_ns, CAP_SYS_ADMIN)) return -EPERM;
/* * CLONE_NEWIPC must detach from the undolist: after switching * to a new ipc namespace, the semaphore arrays from the old * namespace are unreachable. In clone parlance, CLONE_SYSVSEM * means share undolist with parent, so we must forbid using * it along with CLONE_NEWIPC. */ if ((flags & (CLONE_NEWIPC | CLONE_SYSVSEM)) == (CLONE_NEWIPC | CLONE_SYSVSEM)) return -EINVAL;
new_ns = create_new_namespaces(flags, tsk, user_ns, tsk->fs); if (IS_ERR(new_ns)) return PTR_ERR(new_ns);
/* * Create new nsproxy and all of its the associated namespaces. * Return the newly created nsproxy. Do not attach this to the task, * leave it to the caller to do proper locking and attach it to task. */ static struct nsproxy *create_new_namespaces(unsigned long flags, struct task_struct *tsk, struct user_namespace *user_ns, struct fs_struct *new_fs) { struct nsproxy *new_nsp; int err;
// 创建新的 nsproxy new_nsp = create_nsproxy(); if (!new_nsp) return ERR_PTR(-ENOMEM);
mnt namespace: struct mnt_namespace *copy_mnt_ns(unsigned long flags, struct mnt_namespace *ns, struct user_namespace *user_ns, struct fs_struct *new_fs) { struct mnt_namespace *new_ns; struct vfsmount *rootmnt = NULL, *pwdmnt = NULL; struct mount *p, *q; struct mount *old; struct mount *new; int copy_flags;
BUG_ON(!ns);
if (likely(!(flags & CLONE_NEWNS))) { get_mnt_ns(ns); return ns; }
old = ns->root; // 分配新的 mnt namespace new_ns = alloc_mnt_ns(user_ns); if (IS_ERR(new_ns)) return new_ns;
namespace_lock(); /* First pass: copy the tree topology */ // 首先 copy root 路径 copy_flags = CL_COPY_UNBINDABLE | CL_EXPIRE; if (user_ns != ns->user_ns) copy_flags |= CL_SHARED_TO_SLAVE | CL_UNPRIVILEGED; new = copy_tree(old, old->mnt.mnt_root, copy_flags); if (IS_ERR(new)) { namespace_unlock(); free_mnt_ns(new_ns); return ERR_CAST(new); } new_ns->root = new; list_add_tail(&new_ns->list, &new->mnt_list);
/* * Second pass: switch the tsk->fs->* elements and mark new vfsmounts * as belonging to new namespace. We have already acquired a private * fs_struct, so tsk->fs->lock is not needed. */ // 为新进程设置 fs 信息 p = old; q = new; while (p) { q->mnt_ns = new_ns; if (new_fs) { if (&p->mnt == new_fs->root.mnt) { new_fs->root.mnt = mntget(&q->mnt); rootmnt = &p->mnt; } if (&p->mnt == new_fs->pwd.mnt) { new_fs->pwd.mnt = mntget(&q->mnt); pwdmnt = &p->mnt; } } p = next_mnt(p, old); q = next_mnt(q, new); if (!q) break; while (p->mnt.mnt_root != q->mnt.mnt_root) p = next_mnt(p, old); } namespace_unlock();
if (rootmnt) mntput(rootmnt); if (pwdmnt) mntput(pwdmnt);
return new_ns; }
可以看到,mount namespace 在新建时会新建一个新的 namespace,然后将父进程的 namespace 拷贝过来,并将 mount->mnt_ns 指向新的 namespace。接着设置进程的 root 路径以及当前路径到新的 namespace,然后为新进程设置新的 vfs 等。从这里就可以看出,在子进程中进行 mount 操作不会影响到父进程中的 mount 信息。
uts namespace:
1 2 3 4 5 6 7 8
static inline struct uts_namespace *copy_utsname(unsigned long flags, struct user_namespace *user_ns, struct uts_namespace *old_ns) { if (flags & CLONE_NEWUTS) return ERR_PTR(-EINVAL);