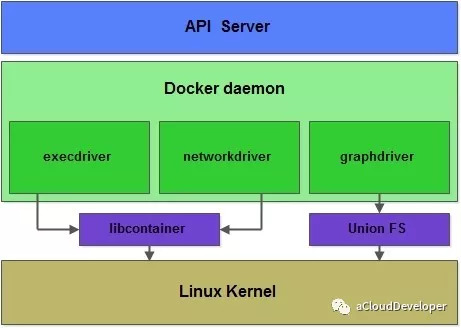
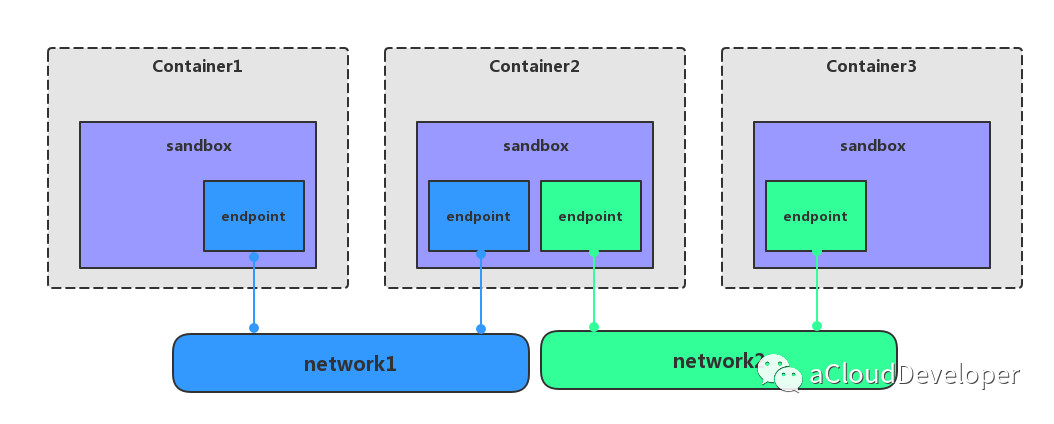
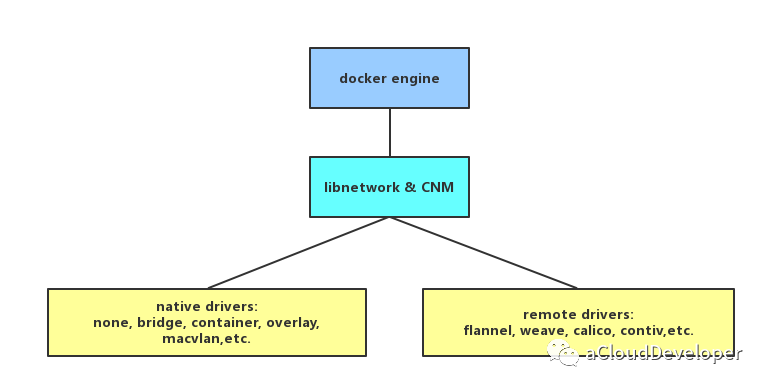
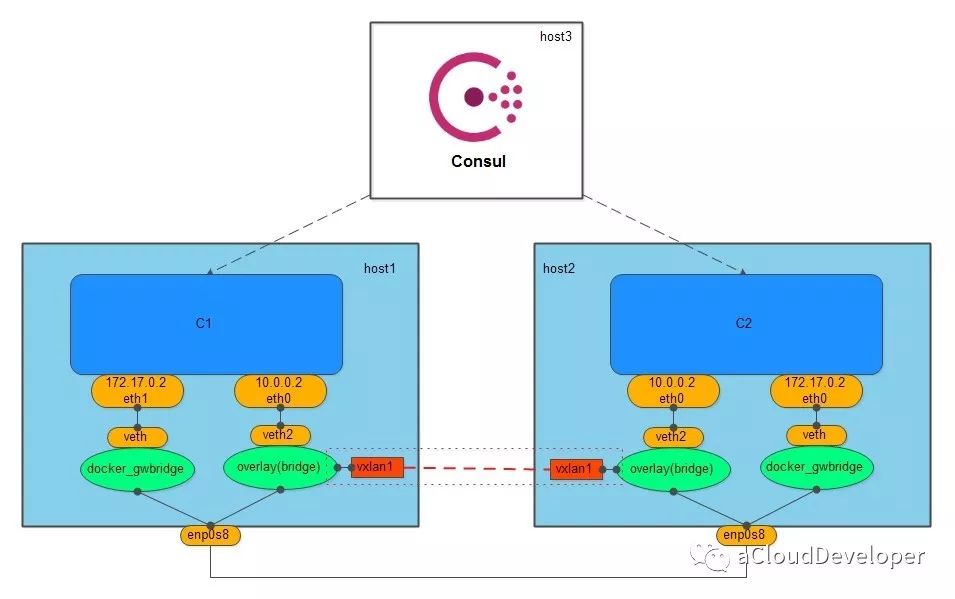
文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
01 写在前面 我的读者当中应该有一部分人是做 DPDK 相关的,我自己虽然现在已经不做 DPDK 了,但对这块仍然有兴趣,今天这篇文章就来总结下 DPDK 的技术栈。注意:这篇文章是小白文,不适合大神哦。
文章从 DPDK 的产生背景,到核心技术,再到应用场景,都进行了阐述,有可能是你见过的讲得最全面的文章了,当然,讲得全面自然会少了深度,你如果不屑忽略就好了。
其实,本文之前已经发过,但在整理的时候不小心删了,索性就重发一次,但这一次多了一些内容,文末我还会推荐一些学习资料,有需要的可以拉到最下面查看获取方法。
02 高性能网络技术 随着云计算产业的异军突起,网络技术的不断创新,越来越多的网络设备基础架构逐步向基于通用处理器平台的架构方向融合,从传统的物理网络到虚拟网络,从扁平化的网络结构到基于 SDN 分层的网络结构,无不体现出这种创新与融合。
这在使得网络变得更加可控制和成本更低的同时,也能够支持大规模用户或应用程序的性能需求,以及海量数据的处理。究其原因,其实是高性能网络编程技术随着网络架构的演进不断突破的一种必然结果。
03 C10K 到 C10M 问题的演进 说到高性能网络编程,一定逃不过 C10K 问题(即单机 1 万个并发连接问题),不过这个问题已经成为历史了,很多技术可以解决它,如常用的 I/O 多路复用模型,select, poll, epoll 等。在此基础上也出了很多优秀的框架,比如 Nginx 基于事件驱动的 Web 服务框架,以及基于 Python 开发的 Tornado 和 Django 这种非阻塞的 Web 框架。
如今,关注的更多是 C10M 问题(即单机 1 千万个并发连接问题)。很多计算机领域的大佬们从硬件上和软件上都提出了多种解决方案。从硬件上,比如说,现在的类似很多 40Gpbs、32-cores、256G RAM 这样配置的 X86 服务器完全可以处理 1 千万个以上的并发连接。
但是从硬件上解决问题就没多大意思了,首先它成本高,其次不通用,最后也没什么挑战,无非就是堆砌硬件而已。所以,抛开硬件不谈,我们看看从软件上该如何解决这个世界难题呢?
这里不得不提一个人,就是 Errata Security 公司的 CEO Robert Graham,他在 Shmoocon 2013 大会上很巧妙地解释了这个问题。有兴趣可以查看其 YouTube 的演进视频: C10M Defending The Internet At Scale。
他提到了 UNIX 的设计初衷其实为电话网络的控制系统而设计的,而不是一般的服务器操作系统,所以,它仅仅是一个负责数据传送的系统,没有所谓的控制层面和数据层面的说法,不适合处理大规模的网络数据包。最后他得出的结论是:
OS 的内核不是解决 C10M 问题的办法,恰恰相反 OS 的内核正式导致 C10M 问题的关键所在。
04 为什么这么说?基于 OS 内核的数据传输有什么弊端? 1、中断处理: 当网络中大量数据包到来时,会产生频繁的硬件中断请求,这些硬件中断可以打断之前较低优先级的软中断或者系统调用的执行过程,如果这种打断频繁的话,将会产生较高的性能开销。
2、内存拷贝: 正常情况下,一个网络数据包从网卡到应用程序需要经过如下的过程:数据从网卡通过 DMA 等方式传到内核开辟的缓冲区,然后从内核空间拷贝到用户态空间,在 Linux 内核协议栈中,这个耗时操作甚至占到了数据包整个处理流程的 57.1%。
3、上下文切换: 频繁到达的硬件中断和软中断都可能随时抢占系统调用的运行,这会产生大量的上下文切换开销。另外,在基于多线程的服务器设计框架中,线程间的调度也会产生频繁的上下文切换开销,同样,锁竞争的耗能也是一个非常严重的问题。
4、局部性失效: 如今主流的处理器都是多个核心的,这意味着一个数据包的处理可能跨多个 CPU 核心,比如一个数据包可能中断在 cpu0,内核态处理在 cpu1,用户态处理在 cpu2,这样跨多个核心,容易造成 CPU 缓存失效,造成局部性失效。如果是 NUMA 架构,更会造成跨 NUMA 访问内存,性能受到很大影响。
5、内存管理: 传统服务器内存页为 4K,为了提高内存的访问速度,避免 cache miss,可以增加 cache 中映射表的条目,但这又会影响 CPU 的检索效率。
综合以上问题,可以看出内核本身就是一个非常大的瓶颈所在。那很明显解决方案就是想办法绕过内核。
05 解决方案探讨 针对以上弊端,分别提出以下技术点进行探讨。
1、控制层和数据层分离: 将数据包处理、内存管理、处理器调度等任务转移到用户空间去完成,而内核仅仅负责部分控制指令的处理。这样就不存在上述所说的系统中断、上下文切换、系统调用、系统调度等等问题。
2、多核技术: 使用多核编程技术代替多线程技术,并设置 CPU 的亲和性,将线程和 CPU 核进行一比一绑定,减少彼此之间调度切换。
3、NUMA 亲和性: 针对 NUMA 系统,尽量使 CPU 核使用所在 NUMA 节点的内存,避免跨内存访问。
4、大页内存: 使用大页内存代替普通的内存,减少 cache-miss。
5、无锁技术: 采用无锁技术解决资源竞争问题。
经研究,目前业内已经出现了很多优秀的集成了上述技术方案的高性能网络数据处理框架,如 6wind、Windriver、Netmap、DPDK 等,其中,Intel 的 DPDK 在众多方案脱颖而出,一骑绝尘。
DPDK 为 Intel 处理器架构下用户空间高效的数据包处理提供了库函数和驱动的支持,它不同于 Linux 系统以通用性设计为目的,而是专注于网络应用中数据包的高性能处理。
也就是 DPDK 绕过了 Linux 内核协议栈对数据包的处理过程,在用户空间实现了一套数据平面来进行数据包的收发与处理。在内核看来,DPDK 就是一个普通的用户态进程,它的编译、连接和加载方式和普通程序没有什么两样。
06 DPDK 的突破 相对传统的基于内核的网络数据处理,DPDK 对从内核层到用户层的网络数据流程进行了重大突破,我们先看看传统的数据流程和 DPDK 中的网络流程有什么不同。
传统 Linux 内核网络数据流程: 1 2 硬件中断--->取包分发至内核线程--->软件中断--->内核线程在协议栈中处理包--->处理完毕通知用户层 用户层收包-->网络层--->逻辑层--->业务层
dpdk 网络数据流程: 1 2 硬件中断--->放弃中断流程 用户层通过设备映射取包--->进入用户层协议栈--->逻辑层--->业务层
下面就具体看看 DPDK 做了哪些突破?
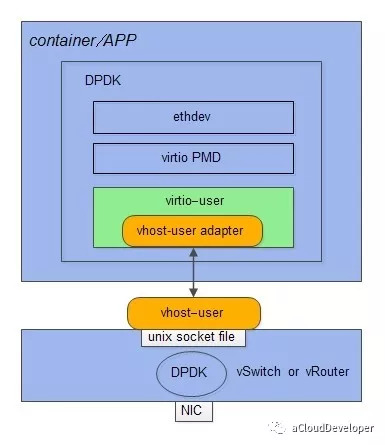
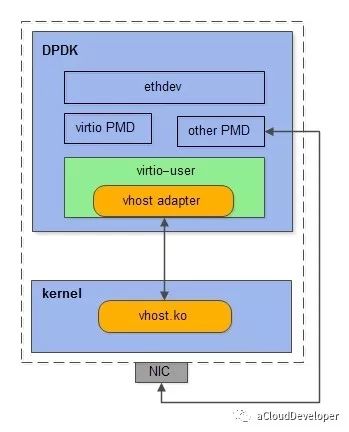
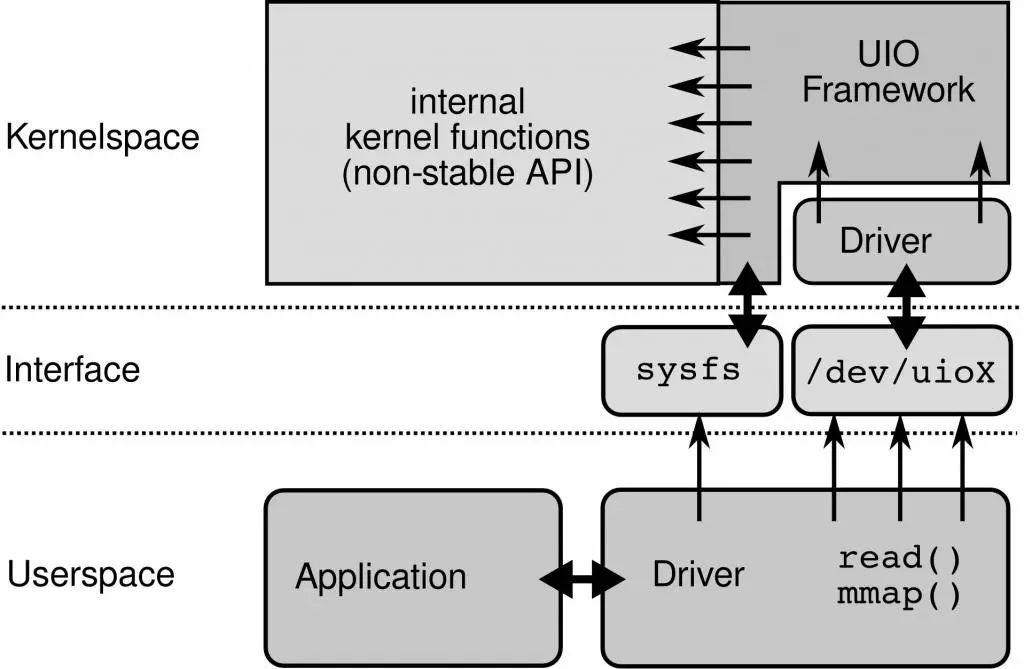
6.1 UIO (用户空间的 I/O 技术)的加持。 DPDK 能够绕过内核协议栈,本质上是得益于 UIO 技术,通过 UIO 能够拦截中断,并重设中断回调行为,从而绕过内核协议栈后续的处理流程。
UIO 设备的实现机制其实是对用户空间暴露文件接口,比如当注册一个 UIO 设备 uioX,就会出现文件 /dev/uioX,对该文件的读写就是对设备内存的读写。除此之外,对设备的控制还可以通过 /sys/class/uio 下的各个文件的读写来完成。
6.2 内存池技术 DPDK 在用户空间实现了一套精巧的内存池技术,内核空间和用户空间的内存交互不进行拷贝,只做控制权转移。这样,当收发数据包时,就减少了内存拷贝的开销。
6.3 大页内存管理 DPDK 实现了一组大页内存分配、使用和释放的 API,上层应用可以很方便使用 API 申请使用大页内存,同时也兼容普通的内存申请。
6.4 无锁环形队列 DPDK 基于 Linux 内核的无锁环形缓冲 kfifo 实现了自己的一套无锁机制。支持单生产者入列/单消费者出列和多生产者入列/多消费者出列操作,在数据传输的时候,降低性能的同时还能保证数据的同步。
6.5 poll-mode 网卡驱动 DPDK 网卡驱动完全抛弃中断模式,基于轮询方式收包,避免了中断开销。
6.6 NUMA DPDK 内存分配上通过 proc 提供的内存信息,使 CPU 核心尽量使用靠近其所在节点的内存,避免了跨 NUMA 节点远程访问内存的性能问题。
6.7 CPU 亲和性 DPDK 利用 CPU 的亲和性将一个线程或多个线程绑定到一个或多个 CPU 上,这样在线程执行过程中,就不会被随意调度,一方面减少了线程间的频繁切换带来的开销,另一方面避免了 CPU 缓存的局部失效性,增加了 CPU 缓存的命中率。
6.8 多核调度框架 DPDK 基于多核架构,一般会有主从核之分,主核负责完成各个模块的初始化,从核负责具体的业务处理。
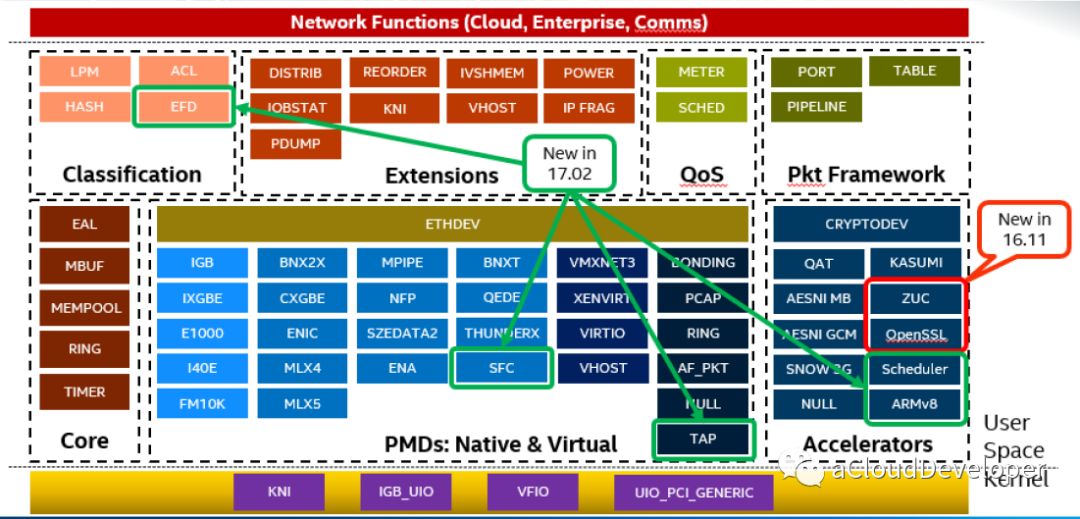
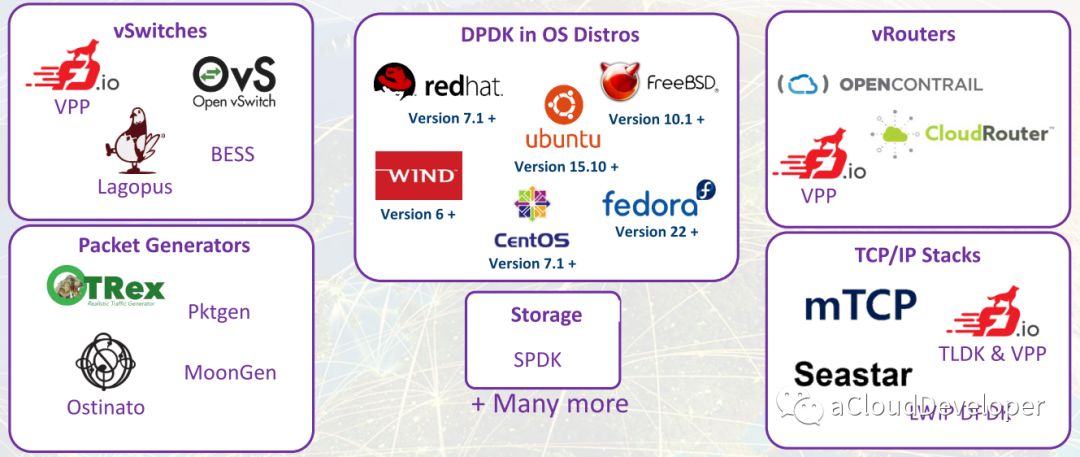
除了上述之外,DPDK 还有很多的技术突破,可以用下面这张图来概之。
07 DPDK 的应用 DPDK 作为优秀的用户空间高性能数据包加速套件,现在已经作为一个“胶水”模块被用在多个网络数据处理方案中,用来提高性能。如下是众多的应用。
数据面(虚拟交换机) OVS
Open vSwitch 是一个多核虚拟交换机平台,支持标准的管理接口和开放可扩展的可编程接口,支持第三方的控制接入。
https://github.com/openvswitch/ovs
VPP
VPP 是 cisco 开源的一个高性能的包处理框架,提供了 交换/路由 功能,在虚拟化环境中,使它可以当做一个虚拟交换机来使用。在一个类 SDN 的处理框架中,它往往充当数据面的角色。经研究表明,VPP 性能要好于 OVS+DPDK 的组合,但它更适用于 NFV,适合做特定功能的网络模块。
https://wiki.fd.io/view/VPP
Lagopus
Lagopus 是另一个多核虚拟交换的实现,功能和 OVS 差不多,支持多种网络协议,如 Ethernet,VLAN,QinQ,MAC-in-MAC,MPLS 和 PBB,以及隧道协议,如 GRE,VxLan 和 GTP。
https://github.com/lagopus/lagopus/blob/master/QUICKSTART.md
Snabb
Snabb 是一个简单且快速的数据包处理工具箱。
https://github.com/SnabbCo/snabbswitch/blob/master/README.md
数据面(虚拟路由器) OPENCONTRAIL
一个集成了 SDN 控制器的虚拟路由器,现在多用在 OpenStack 中,结合 Neutron 为 OpenStack 提供一站式的网络支持。
http://www.opencontrail.org/
CloudRouter
一个分布式的路由器。
https://cloudrouter.org/
用户空间协议栈 mTCP
mTCP 是一个针对多核系统的高可扩展性的用户空间 TCP/IP 协议栈。
https://github.com/eunyoung14/mtcp/blob/master/README
IwIP
IwIP 针对 RAM 平台的精简版的 TCP/IP 协议栈实现。
http://git.savannah.gnu.org/cgit/lwip.git/tree/README
Seastar
Seastar 是一个开源的,基于 C++ 11/14 feature,支持高并发和低延迟的异步编程高性能库。
http://www.seastar-project.org/
f-stack
腾讯开源的用户空间协议栈,移植于 FreeBSD协议栈,粘合了 POSIX API,上层应用(协程框架,Nginx,Redis),纯 C 编写,易上手。
https://github.com/f-stack/f-stack
存储加速 SPDK
SPDK 是 DPDK 的孪生兄弟,专注存储性能加速,目前的火热程度丝毫不亚于 DPDK,Intel 近来对 SPDK 特别重视,隔三差五就发布新版本。
https://github.com/spdk/spdk
08 总结 DPDK 绕过了 Linux 内核协议栈,加速数据的处理,用户可以在用户空间定制协议栈,满足自己的应用需求,目前出现了很多基于 DPDK 的高性能网络框架,OVS 和 VPP 是常用的数据面框架,mTCP 和 f-stack 是常用的用户态协议栈,SPDK 是存储性能加速器,很多大公司都在使用 DPDK 来优化网络性能。
PS:本文所有的图来自网络,侵权必删。
09 DPDK 资料推荐 在我看来,DPDK 最好的学习资料是官网,没有之一:
http://core.dpdk.org/doc/
其次是看 Intel 技术专家出的书 《深入浅出 DPDK》。
本书详细介绍了DPDK 技术发展趋势,数据包处理,硬件加速技术,包处理和虚拟化 ,以及 DPDK 技术在 SDN,NFV ,网络存储等领域的实际应用。
本书是国内第一本全面的阐述网络数据面的核心技术的书籍,面向 IT 网络通讯行业的从业人员,以及大专院校的学生,用通俗易懂的文字打开了一扇通向新一代网络处理架构的大门。
本书我有电子版(但只有一部分,推荐大家买书),需要的公众号后台回复 “DPDK” 查看获取方式。
除了书之外,就是看大牛的博客,加入相关的群和优秀的人一起学习,我整理了几份网上较好的博客资料,和书一起附赠,如果想加群学习,回复 “加群”。
PS:文章未经我允许,不得转载,否则后果自负。
–END–
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。