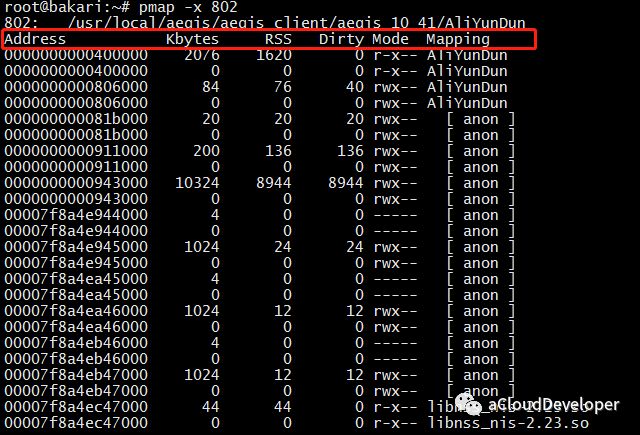
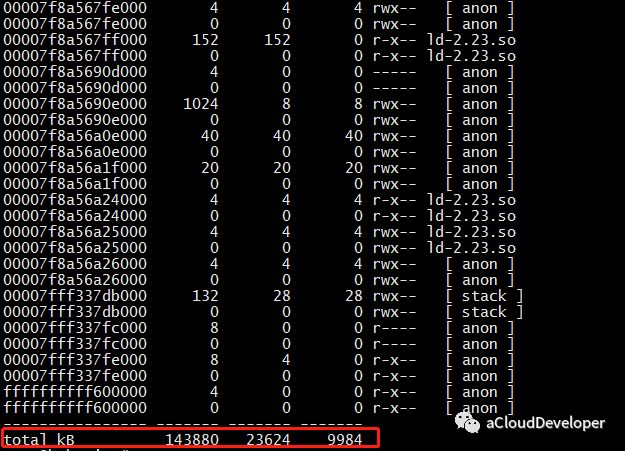
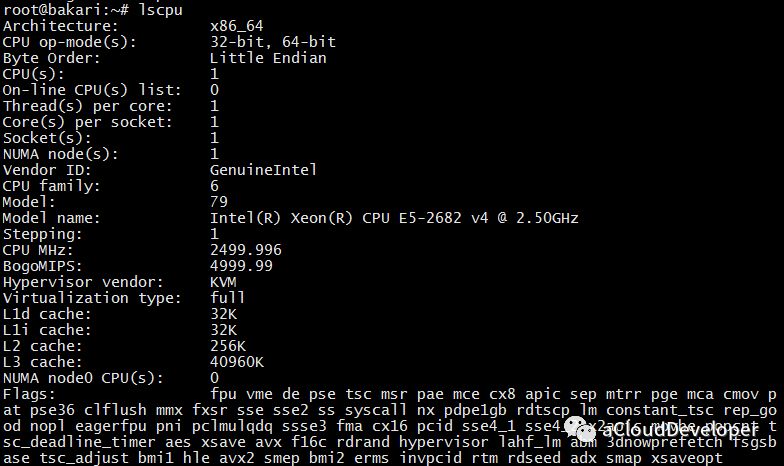
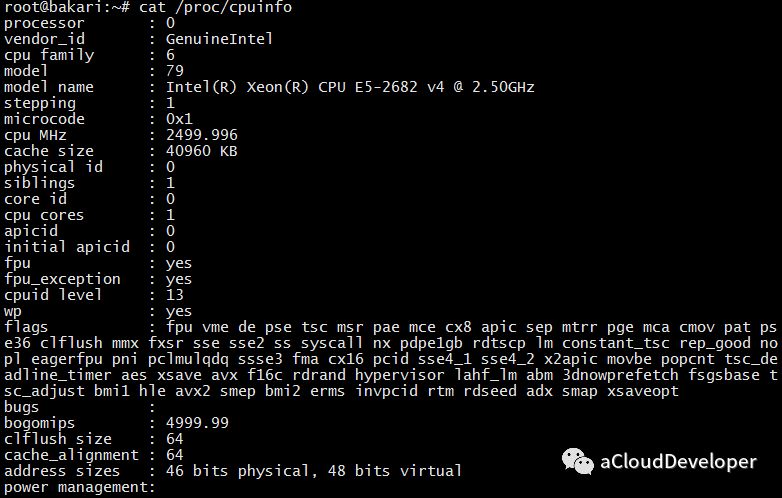
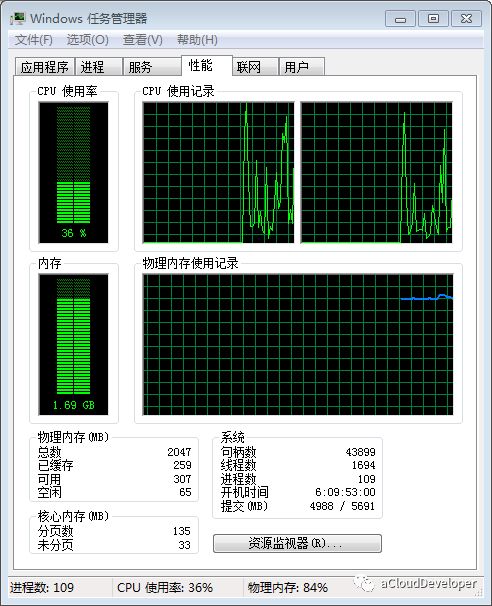
Linux # cat /proc/cpuinfo | grep "physical id" physical id : 0 physical id : 0 physical id : 0 physical id : 0 physical id : 1 physical id : 1 physical id : 1 physical id : 1
============================================================ Core and Socket Information (as reported by '/proc/cpuinfo') ============================================================
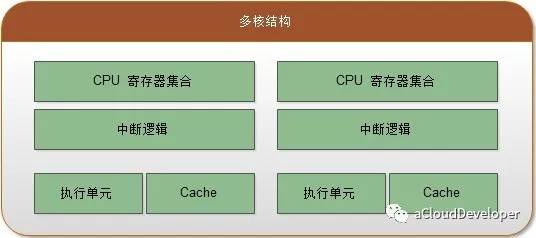
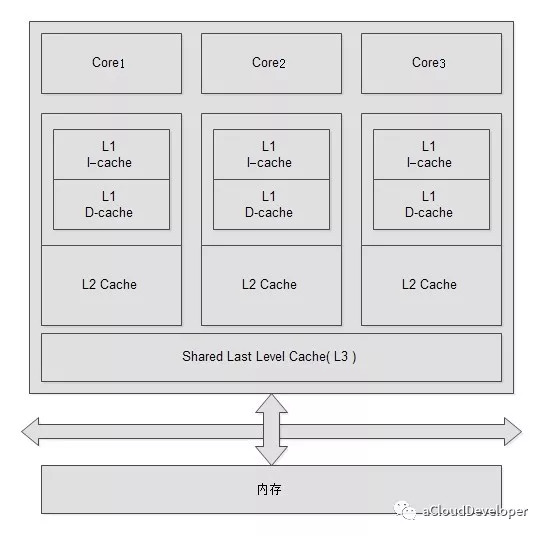
随着计算机技术(特别是以芯片为主的硬件技术)的快速发展,CPU 架构逐步从以前的单核时代进阶到如今的多核时代,在多核时代里,多颗 CPU 核心构成了一个小型的“微观世界”。每颗 CPU 各司其职,并与其他 CPU 交互,共同支撑起了一个“物理世界”。从这个意义上来看,我们更愿意称这样的“微观世界”为 CPU 拓扑,就像一个物理网络一样,各个网络节点通过拓扑关系建立起连接来支撑起整个通信系统。
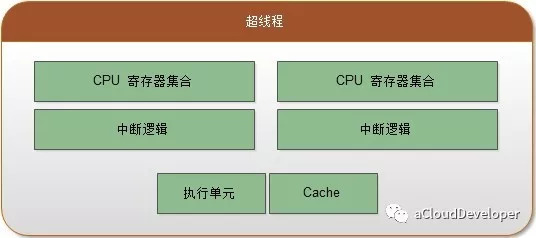
单核 or 多核 or 多 CPU or 超线程 ?
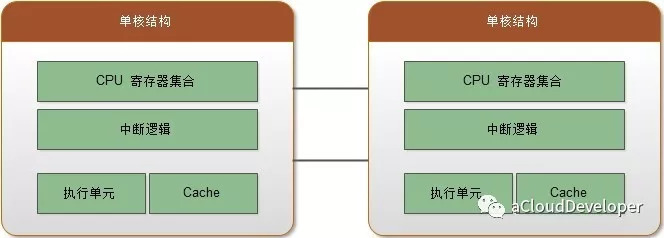
在单核时代,为了提升 CPU 的处理能力,普遍的做法是提高 CPU 的主频率,但一味地提高频率对于 CPU 的功耗也是影响很大的(CPU 的功耗正比于主频的三次方)。
如果说前面咱们讨论的是 CPU 内部的“微观世界”,那么本节将跳出来,探讨一个系统级的“宏观世界”。
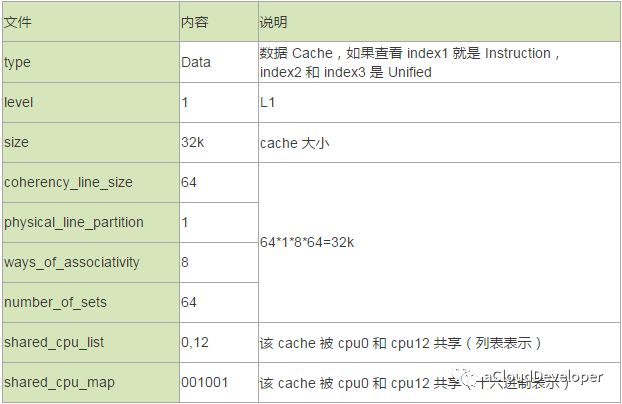
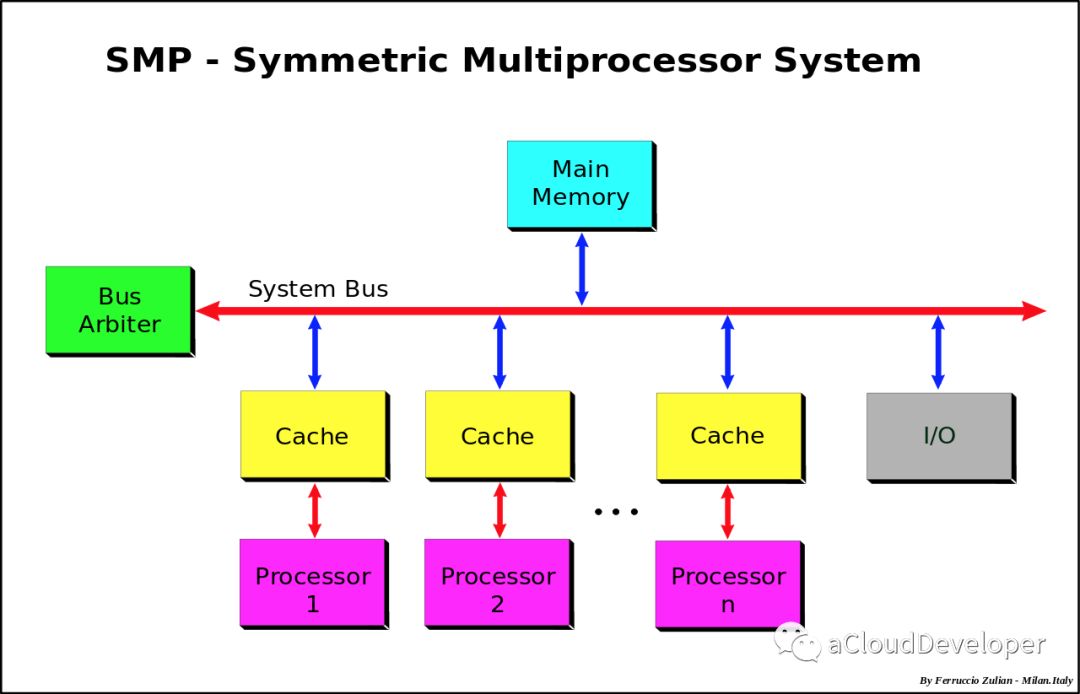
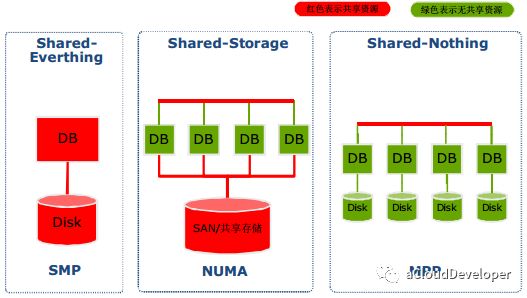
首先是 SMP,对称多处理器系统,指的是一种多个 CPU 处理器共享资源的电脑硬件架构,其中,每个 CPU 没有主从之分,地位平等,它们共享相同的物理资源,包括总线、内存、IO、操作系统等。每个 CPU 访问内存所用时间都是相同的,因此这种系统也被称为一致存储访问结构(UMA,Uniform Memory Access)。
ls /sys/devices/system/node/ # 如果只看到一个 node0 那就是 SMP 架构
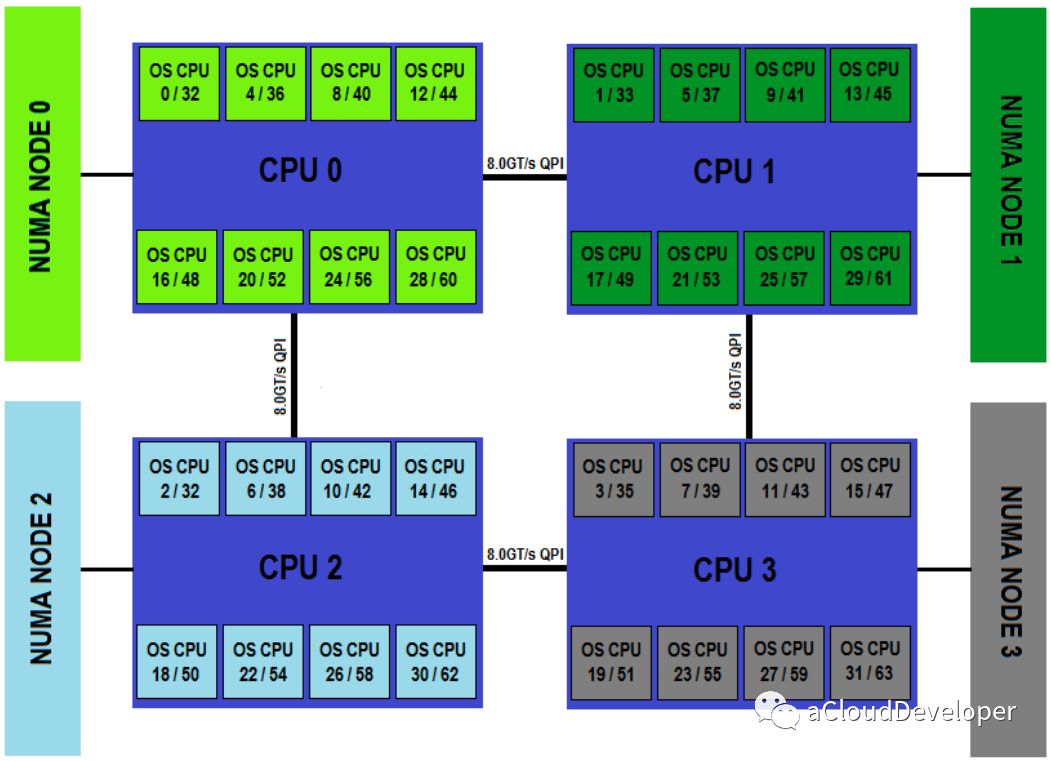
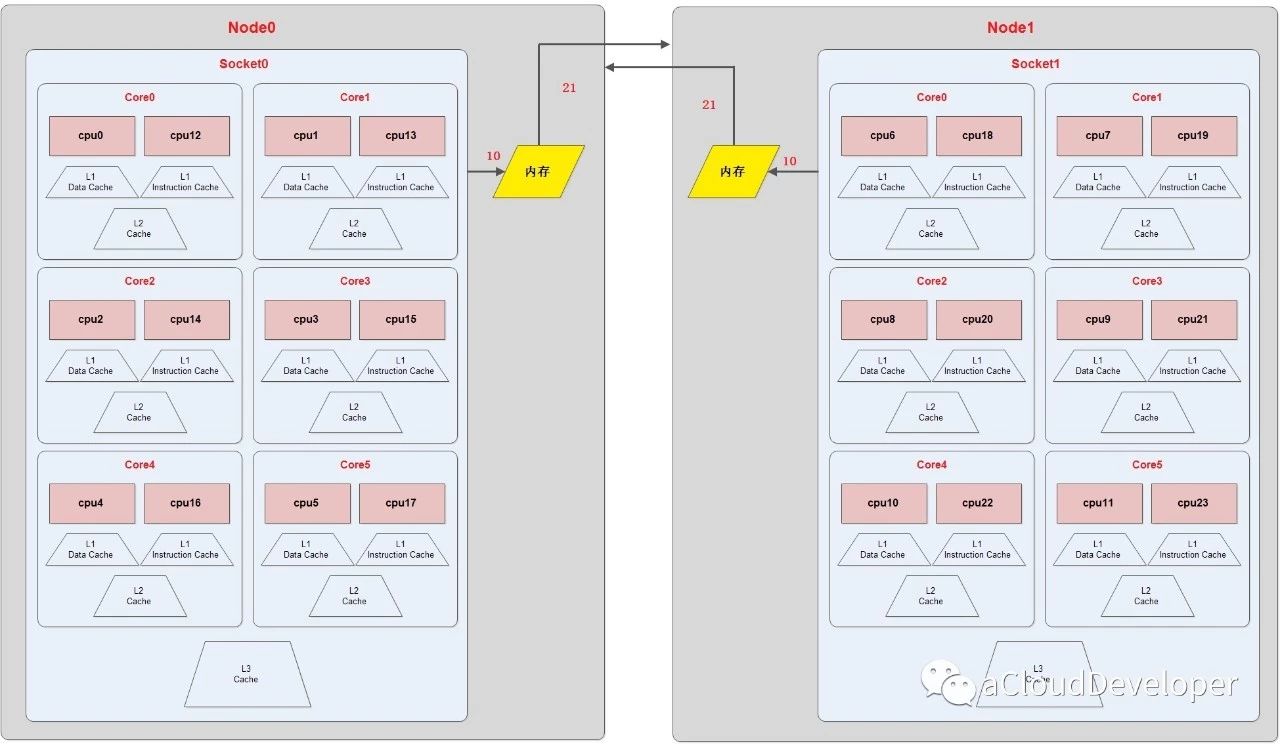
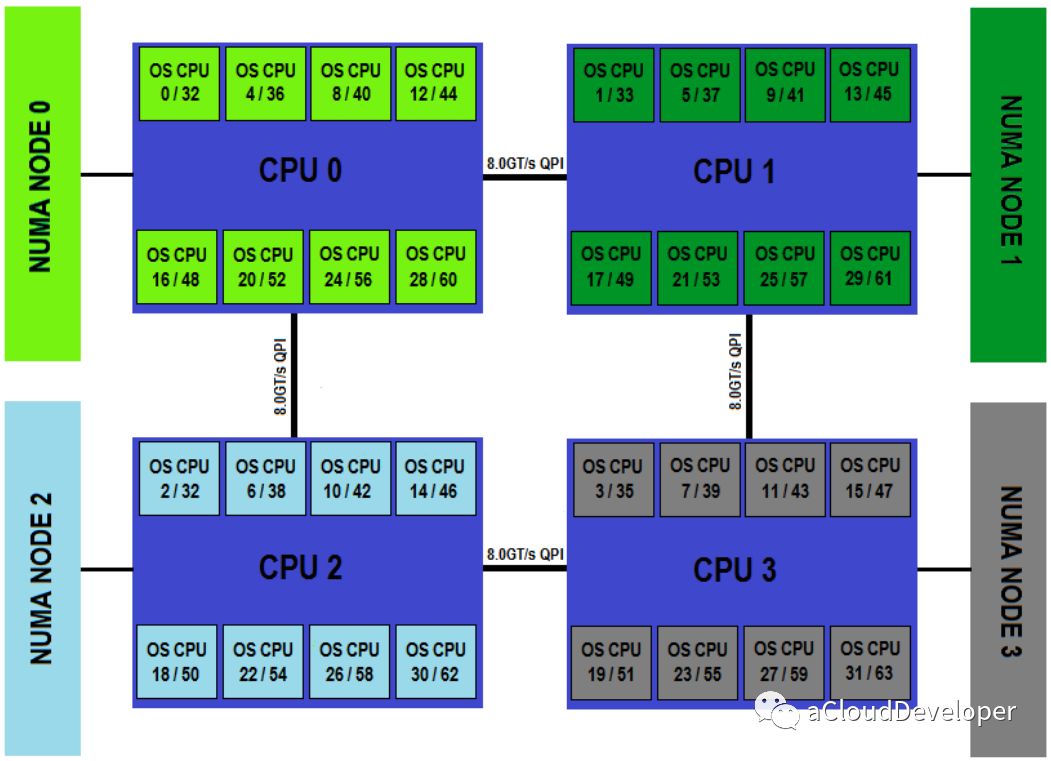
为了应对大规模的系统要求(特别是云计算环境),就研制出了 NUMA 结构,即非一致存储访问结构。
这种结构引入了 CPU 分组的概念,用 Node 来表示,一个 Node 可能包含多个物理 CPU 封装,从而包含多个 CPU 物理核心。每个 Node 有自己独立的资源,包括内存、IO 等。每个 Node 之间可以通过互联模块总线(QPI)进行通信,所以,也就意味着每个 Node 上的 CPU 都可以访问到整个系统中的所有内存,但很显然,访问远端 Node 的内存比访问本地内存要耗时很多,这也是 NUMA 架构的问题所在,我们在基于 NUMA 架构开发上层应用程序要尽可能避免跨 Node 内存访问。
NUMA 架构在 SMP 架构的基础上通过分组的方式增强了可扩展性,但从性能上看,随着 CPU 数量的增加,并不能线性增加系统性能,原因就在于跨 Node 内存访问的问题。所以,一般 NUMA 架构最多支持几百个 CPU 就不错了。
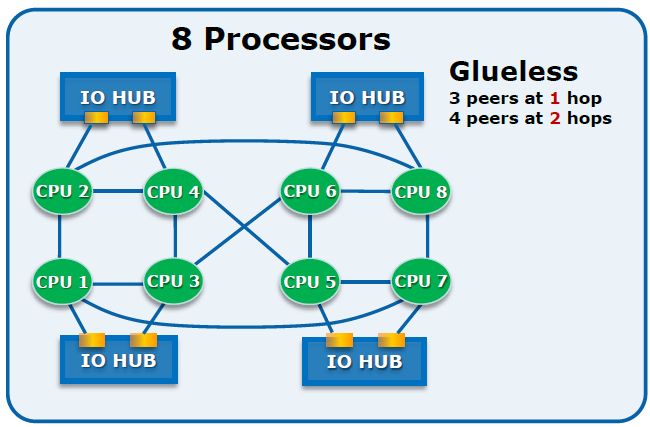
但对于很多大型计算密集型的系统来说,NUMA 显然有些吃力,所以,后来又出现了 MPP 架构,即海量并行处理架构。这种架构也有分组的概念,但和 NUMA 不同的是,它不存在异地内存访问的问题,每个分组内的 CPU 都有自己本地的内存、IO,并且不与其他 CPU 共享,是一种完全无共享的架构,因此它的扩展性最好,可以支持多达数千个 CPU 的量级。
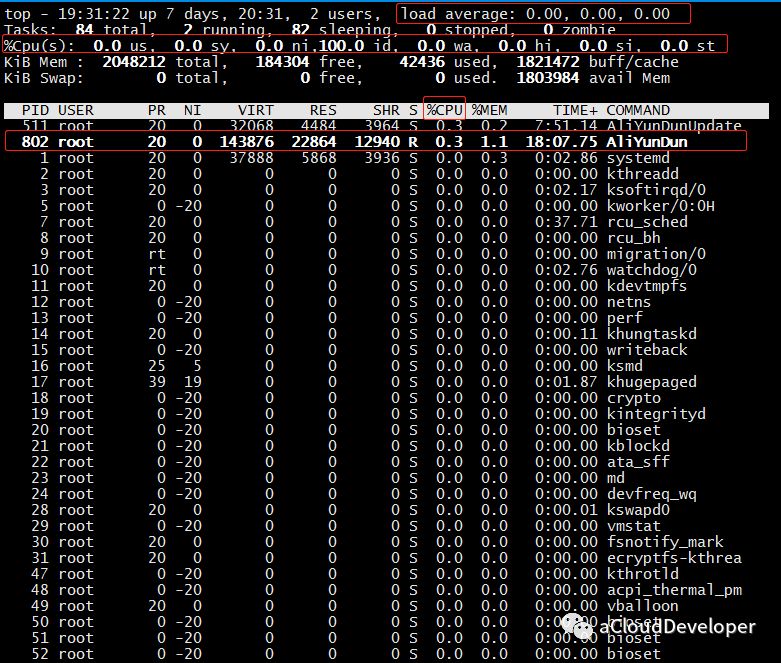
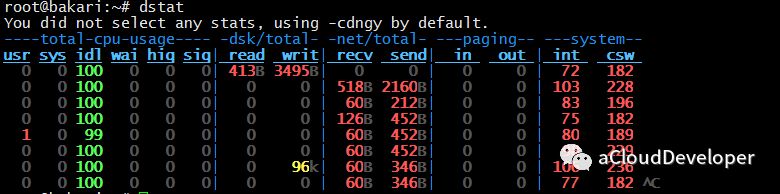
%Cpu(s):表示当前 CPU 的使用情况,如果要查看所有核(逻辑核)的使用情况,可以按下数字 “1” 查看。这里有几个参数,表示如下:
1 2 3 4 5 6 7 8
- us 用户空间占用 CPU 时间比例 - sy 系统占用 CPU 时间比例 - ni 用户空间改变过优先级的进程占用 CPU 时间比例 - id CPU 空闲时间比 - wa IO等待时间比(IO等待高时,可能是磁盘性能有问题了) - hi 硬件中断 - si 软件中断 - st steal time
每个进程的使用情况:这里可以罗列每个进程的使用情况,包括内存和 CPU 的,如果要看某个具体的进程,可以使用 top -p pid 查看。
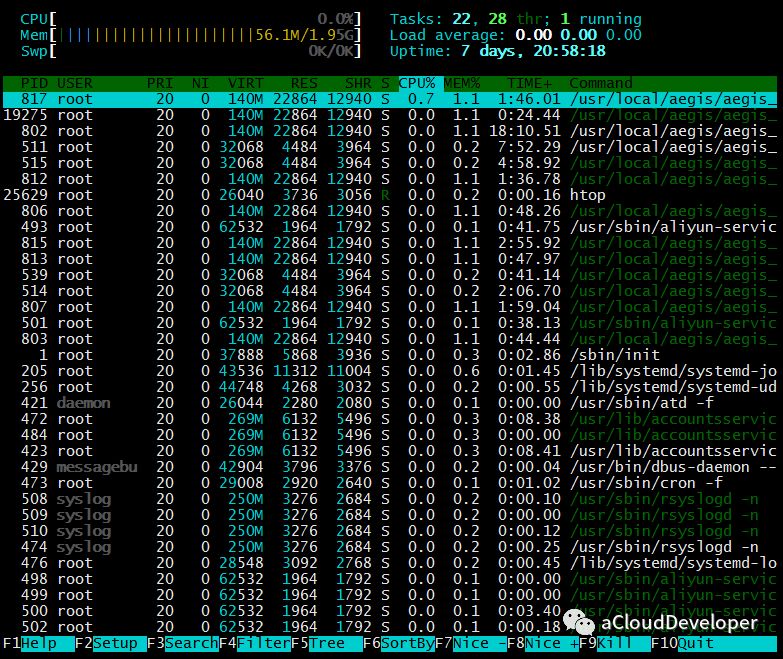
和 top 一样的还有一个改进版的工具:htop,功能和 top 一样的,只不过比 top 表现更炫酷,使用更方便,可以看下它的效果。