文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
这是 Linux 性能分析系列的第四篇。
比较宽泛地讲,网络方向的性能分析既包括主机测的网络配置查看、监控,又包括网络链路上的包转发时延、吞吐量、带宽等指标分析。包括但不限于以下分析工具:
ping:测试网络连通性
ifconfig:接口配置
ip:网络接口统计信息
netsat:多种网络栈和接口统计信息
ifstat:接口网络流量监控工具
netcat:快速构建网络连接
tcpdump:抓包工具
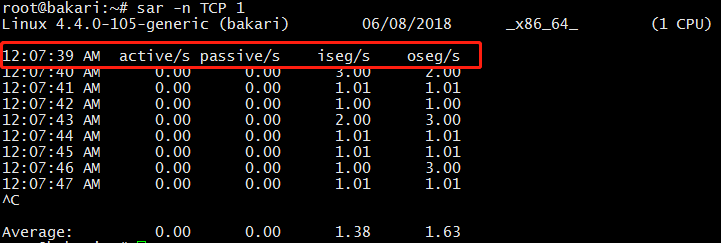
sar:统计信息历史
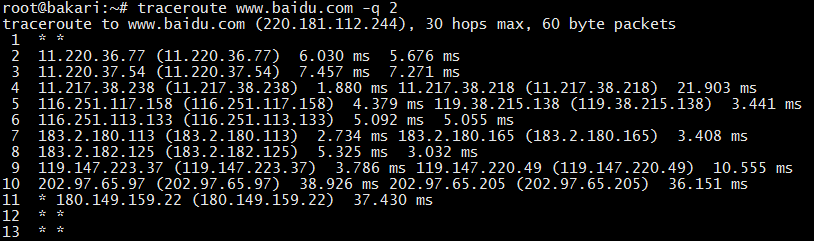
traceroute:测试网络路由
pathchar:确定网络路径特征
dtrace:TCP/IP 栈跟踪
iperf / netperf / netserver:网络性能测试工具
perf :性能分析神器
本文先来看前面 7 个。
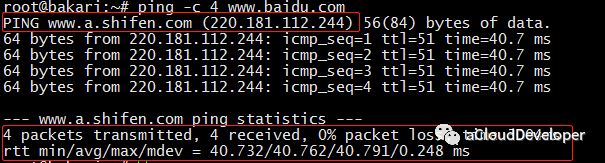
ping ping 发送 ICMP echo 数据包来探测网络的连通性,除了能直观地看出网络的连通状况外,还能获得本次连接的往返时间(RTT 时间),丢包情况,以及访问的域名所对应的 IP 地址(使用 DNS 域名解析),比如:
我们 ping baidu.com,-c参数指定发包数。可以看到,解析到了 baidu 的一台服务器 IP 地址为 220.181.112.244。RTT 时间的最小、平均、最大和算术平均差分别是 40.732ms、40.762ms、40.791ms 和 0.248。
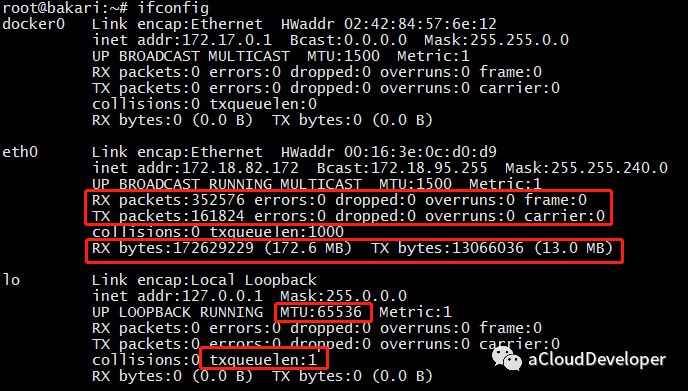
ifconfig ifconfig 命令被用于配置和显示 Linux 内核中网络接口的统计信息。通过这些统计信息,我们也能够进行一定的网络性能调优。
1)ifconfig 显示网络接口配置信息
其中,RX/TX packets 是对接收/发送数据包的情况统计,包括错误的包,丢掉多少包等。RX/TX bytes 是接收/发送数据字节数统计。其余还有很多参数,就不一一述说了,性能调优时可以重点关注 MTU(最大传输单元) 和 txqueuelen(发送队列长度),比如可以用下面的命令来对这两个参数进行微调:1 2 ifconfig eth0 txqueuelen 2000 ifconfig eth0 mtu 1500
2)网络接口地址配置
ifconfig 还常用来配置网口的地址,比如:1 2 ifconfig eth0 add 33ffe:3240:800:1005::2/64 #为网卡eth0配置IPv6地址 ifconfig eth0 del 33ffe:3240:800:1005::2/64 #为网卡eth0删除IPv6地址
修改MAC地址:1 ifconfig eth0 hw ether 00:AA:BB:CC:dd:EE
配置IP地址:1 2 3 ifconfig eth0 192.168.2.10 ifconfig eth0 192.168.2.10 netmask 255.255.255.0 ifconfig eth0 192.168.2.10 netmask 255.255.255.0 broadcast 192.168.2.255
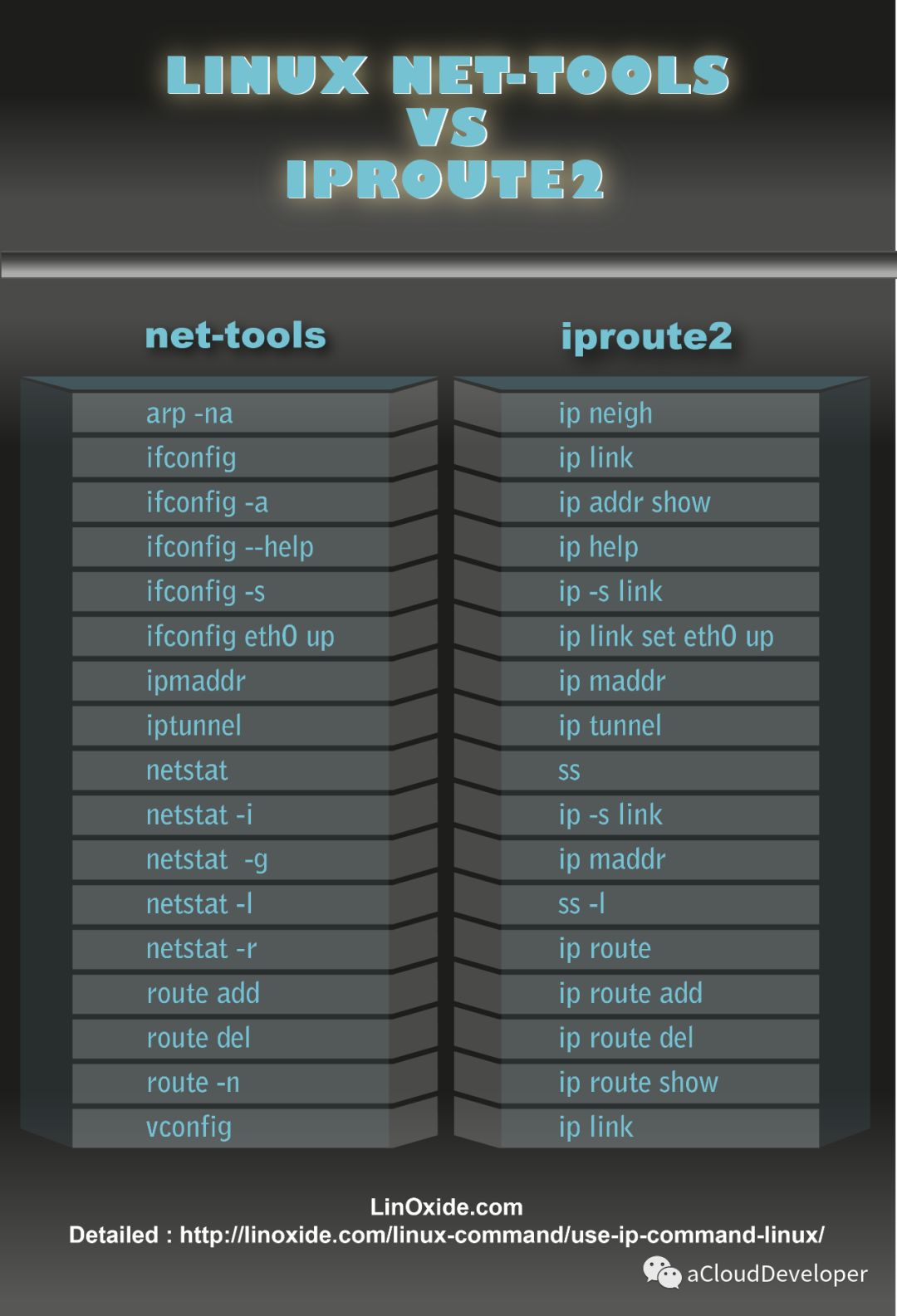
IP ip 命令用来显示或设置 Linux 主机的网络接口、路由、网络设备、策略路由和隧道等信息,是 Linux 下功能强大的网络配置工具,旨在替代 ifconfig 命令,如下显示 IP 命令的强大之处,功能涵盖到 ifconfig、netstat、route 三个命令。
netstat netstat 可以查看整个 Linux 系统关于网络的情况,是一个集多钟网络工具于一身的组合工具。
常用的选项包括以下几个:
默认:列出连接的套接字
-a:列出所有套接字的信息
-s:各种网络协议栈统计信息
-i:网络接口信息
-r:列出路由表
-l:仅列出有在 Listen 的服务状态
-p:显示 PID 和进程名称
各参数组合使用实例如下:
netstat -at 列出所有 TCP 端口
netstat -au 列出所有 UDP 端口
netstat -lt 列出所有监听 TCP 端口的 socket
netstat -lu 列出所有监听 UDP 端口的 socket
netstat -lx 列出所有监听 UNIX 端口的 socket
netstat -ap | grep ssh 找出程序运行的端口
netstat -an | grep ‘:80’ 找出运行在指定端口的进程
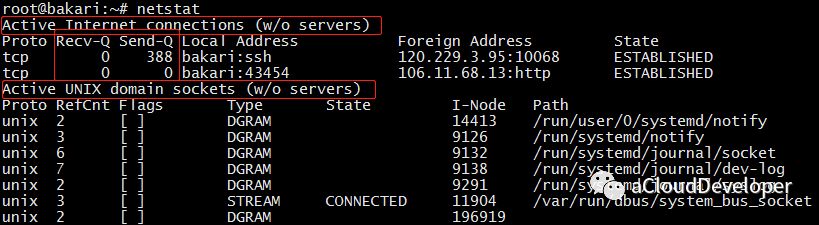
1)netstat 默认显示连接的套接字数据
整体上来看,输出结果包括两个部分:
Active Internet connections :有源 TCP 连接,其中 Recv-Q 和 Send-Q 指的是接收队列和发送队列,这些数字一般都是 0,如果不是,说明请求包和回包正在队列中堆积。
Active UNIX domain sockets:有源 UNIX 域套接口,其中 proto 显示连接使用的协议,RefCnt 表示连接到本套接口上的进程号,Types 是套接口的类型,State 是套接口当前的状态,Path 是连接到套接口的进程使用的路径名。
2)netstat -i 显示网络接口信息
接口信息包括网络接口名称(Iface)、MTU,以及一系列接收(RX-)和传输(TX-)的指标。其中 OK 表示传输成功的包,ERR 是错误包,DRP 是丢包,OVR 是超限包。
这些参数有助于我们对网络收包情况进行分析,从而判断瓶颈所在。
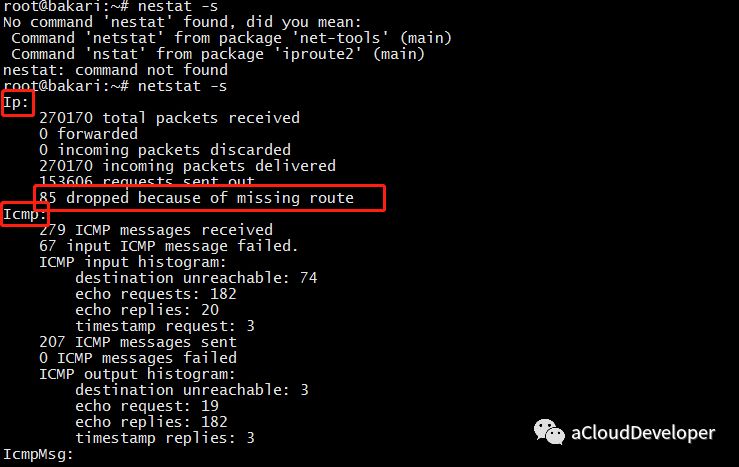
3)netstat -s 显示所有网络协议栈的信息
可以看到,这条命令能够显示每个协议详细的信息,这有助于我们针对协议栈进行更细粒度的分析。
4)netstat -r 显示路由表信息
这条命令能够看到主机路由表的一个情况。当然查路由我们也可以用 ip route 和 route 命令,这个命令显示的信息会更详细一些。
ifstat ifstat 主要用来监测主机网口的网络流量,常用的选项包括:
-a:监测主机所有网口
-i:指定要监测的网口
-t:在每行输出信息前加上时间戳
-b:以 Kbit/s 显示流量数据,而不是默认的 KB/s
delay:采样间隔(单位是 s),即每隔 delay 的时间输出一次统计信息
count:采样次数,即共输出 count 次统计信息
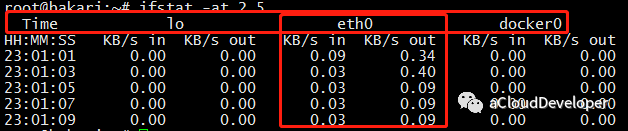
比如,通过以下命令统计主机所有网口某一段时间内的流量数据:
可以看出,分别统计了三个网口的流量数据,前面输出的时间戳,有助于我们统计一段时间内各网口总的输入、输出流量。
netcat netcat,简称 nc,命令简单,但功能强大,在排查网络故障时非常有用,因此它也在众多网络工具中有着“瑞士军刀”的美誉。
它主要被用来构建网络连接。可以以客户端和服务端的方式运行,当以服务端方式运行时,它负责监听某个端口并接受客户端的连接,因此可以用它来调试客户端程序;当以客户端方式运行时,它负责向服务端发起连接并收发数据,因此也可以用它来调试服务端程序,此时它有点像 Telnet 程序。
常用的选项包括以下几种:
-l:以服务端的方式运行,监听指定的端口。默认是以客户端的方式运行。
-k:重复接受并处理某个端口上的所有连接,必须与 -l 一起使用。
-n:使用 IP 地址表示主机,而不是主机名,使用数字表示端口号,而不是服务名称。
-p:当以客户端运行时,指定端口号。
-s:设置本地主机发出的数据包的 IP 地址。
-C:将 CR 和 LF 两个字符作为结束符。
-U:使用 UNIX 本地域套接字通信。
-u:使用 UDP 协议通信,默认使用的是 TCP 协议。
-w:如果 nc 客户端在指定的时间内未检测到任何输入,则退出。
-X:当 nc 客户端与代理服务器通信时,该选项指定它们之间的通信协议,目前支持的代理协议包括 “4”(SOCKS v.4),“5”(SOCKS v.5)和 “connect” (HTTPs Proxy),默认使用 SOCKS v.5。
-x:指定目标代理服务器的 IP 地址和端口号。
下面举一个简单的例子,使用 nc 命令发送消息:
然后,启动客户端,用 nc -p 1234 127.0.0.1 12345 使用 1234 端口连接服务器 127.0.0.1::12345。
接着就可以在两端互发数据了。这里只是抛砖引玉,更多例子大家可以多实践。
tcpdump 最后是 tcpdump,强大的网络抓包工具。虽然有 wireshark 这样更易使用的图形化抓包工具,但 tcpdump 仍然是网络排错的必备利器。
tcpdump 选项很多,我就不一一列举了,大家可以看文章末尾的引用来进一步了解。这里列举几种 tcpdump 常用的用法。
1)捕获某主机的数据包
比如想要捕获主机 200.200.200.100 上所有收到和发出的所有数据包,使用:1 tcpdump host 200.200.200.100
2)捕获多个主机的数据包
比如要捕获主机 200.200.200.1 和主机 200.200.200.2 或 200.200.200.3 的通信,使用:1 tcpdump host 200.200.200.1 and \(200.200.200.2 or \)
同样要捕获主机 200.200.200.1 除了和主机 200.200.200.2 之外所有主机通信的 IP 包。使用:1 tcpdump ip host 200.200.200.1 and ! 200.200.200.2
3)捕获某主机接收或发出的某种协议类型的包 1 tcpdump tcp port 23 host 200.200.200.1
4)捕获某端口相关的数据包
比如捕获在端口 6666 上通过的包,使用:
5)捕获某网口的数据包
下面还是举个例子,抓取 TCP 三次握手的包:
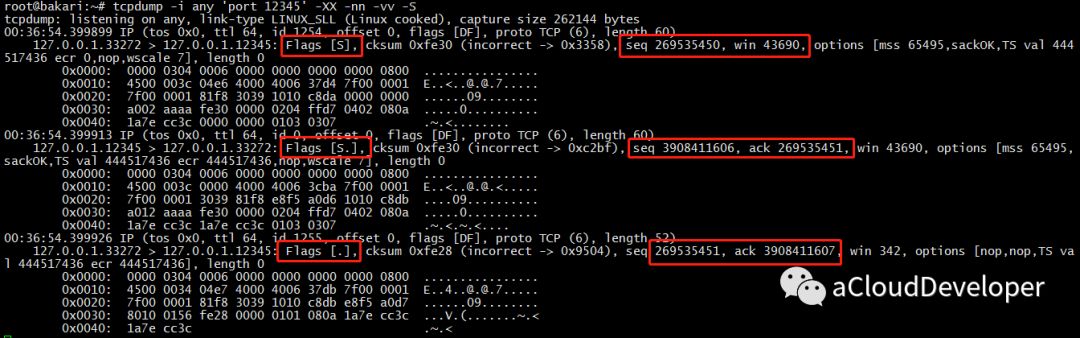
接着,启动 tcpdump 监听端口 12345 上通过的包:1 tcpdump -i any 'port 12345' -XX -nn -vv -S
然后,再用 nc 启动客户端,连接服务端:
最后,我们看到 tcpdump 抓到包如下:
怎么分析是 TCP 的三次握手,就当做小作业留给大家吧,其实看图就已经很明显了。
总结 本文总结了几种初级的网络工具,一般的网络性能分析,通过组合以上几种工具,基本都能应付,但对于复杂的问题,以上工具可能就无能为力了。更多高阶的工具将在下文送上,敬请期待。
Reference:
ip 和 ipconfig:https://blog.csdn.net/freeking101/article/details/68939059
性能之巅:Linux网络性能分析工具http://www.infoq.com/cn/articles/linux-networking-performance-analytics
抓包工具tcpdump用法说明https://www.cnblogs.com/f-ck-need-u/p/7064286.html
PS:文章未经我允许,不得转载,否则后果自负。
–END–
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。