文章首发于我的公众号「Linux云计算网络」,欢迎关注,第一时间掌握技术干货!
1 2 本文是一篇翻译,翻译自: https://software.intel.com/en-us/blogs/2015/06/12/user-space-networking-fuels-nfv-performance,文章有点老了,15年写的,但是文章总结了一些用户态的协议栈,很有学习参考的意义。
用户态协议栈 如今,作为一个网络空间的软件开发人员是非常激动人心的,因为工程师的角色随着这个世界的规则在逐渐发生改变。
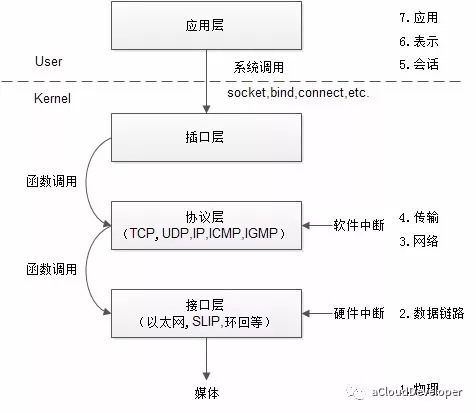
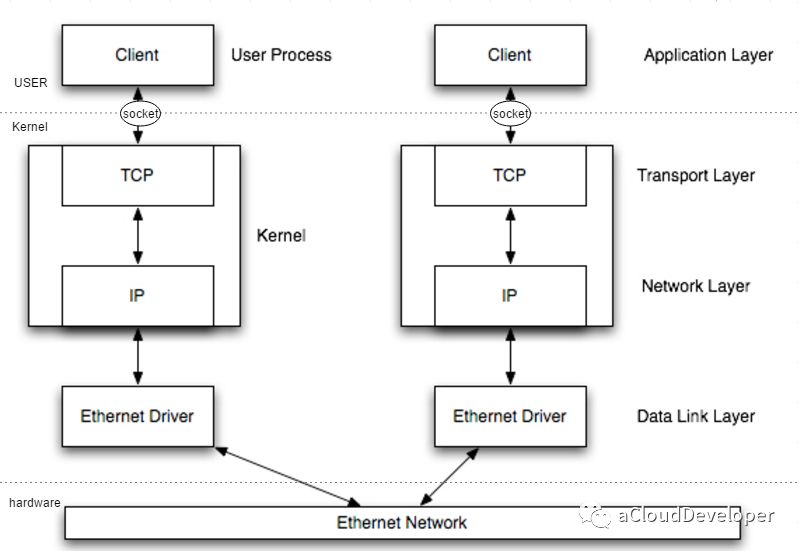
过去这 15 年来,人们对高性能网络做了很多努力,网络模型也发生了很多改变,起初,数据包的收发都要推送到内核才能完成,现在,不用内核态的参与也可以完成。这种改变的背后主要是在解决以下的几个问题:1)用户态和内核态上下文切换的开销;2)软硬中断的开销;3)数据拷贝的开销等等。
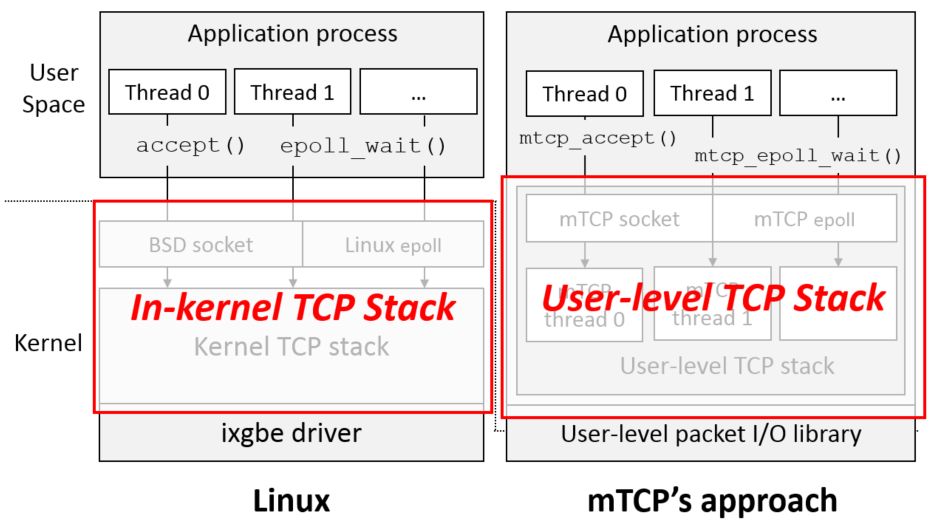
最近,很多人在讨论 mTCP——一个实现了用户态协议栈的开源库,这种技术在很大程度上就颠覆了传统的网络模型,使得网络收发包的效率大大提升。它充分利用了 CPU 的亲和性,共享内存,批处理等技术来实现高效的 I/O 事件。与之类似的技术也相继被提出。
实验表明,mTCP 这种用户态协议栈,相较原生的内核协议栈,在处理多种流行的应用时的性能得到较大提升,如 SSLShader 提升了 33%,lighttpd 提升了 320%。
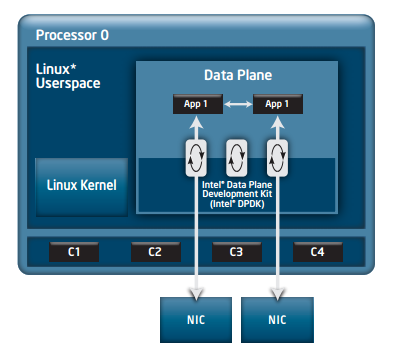
软件形态的改变离不开硬件的革新。由以前的单核系统到如今多核系统的性能扩展,直接导致了网络软件架构的改变。例如,以前内核所做的所有功能和处理,包括网络驱动程序,现在都可以被直接放到用户空间中来实现,应用程序可以直接访问底层的 NUMA 结构,利用 CPU 的亲和性,以及多核特性并行处理任务。这种设计避免了上下文之间的切换开销,可以显著降低数据传输的延迟和 CPU 使用,同时提高吞吐量和带宽。另外,提供一种运行到完成(run-to-completion)的模型能够让不同的核独立并行地完成不同的任务。
随着网络的发展,我们现在看到了大量的开源项目,都在将内核协议栈移到用户空间来做。它们的做法存在一些区别,像 mTCP,它的协议栈是从零开始开发的,而其他很多项目则是基于 FreeBSD 的来做,这主要是因为 FreeBSD 的协议栈具有 “最健壮的网络协议栈的声誉”,此外,很多存储解决方案也是采用的 FreeBSD 来作为其核心操作系统。当然,Linux 协议栈也是可以采用的。
这些用户态协议栈怎么做到绕过内核的,这就离不开 DPDK 的支持。利用 DPDK,用户态协议栈可以创建一个中断来将数据包从 NIC 的缓冲区直接映射到用户空间,然后利用协议栈的特性来管理 TCP/IP 数据包的处理和传输。
DPDK 还可以作为一些 vSwitch(虚拟交换机)的加速器,这些 vSwitch 包含 OpenFlow 协议的完整实现,以及与 OpenStack Neutron 的整合。
下面,我们收集了一些发现的开源项目,无论你决定使用一个 vSwitch 还是一个完整的网络协议栈,网络开发人员都有很多选择,可以将应用程序移到用户空间,并在多核系统上扩展性能。
DPDK-Enabled vSwitch: OVS
Open vSwitch 是一个多核虚拟交换机平台,支持标准的管理接口和开放可扩展的可编程接口,支持第三方的控制接入。https://github.com/openvswitch/ovs
Lagopus
Lagopus 是另一个多核虚拟交换的实现,功能和 OVS 差不多,支持多种网络协议,如 Ethernet,VLAN,QinQ,MAC-in-MAC,MPLS 和 PBB,以及隧道协议,如 GRE,VxLan 和 GTP。https://github.com/lagopus/lagopus/blob/master/QUICKSTART.md
Snabb
Snabb 是一个简单且快速的数据包处理工具箱。https://github.com/SnabbCo/snabbswitch/blob/master/README.md
xDPd
xDPd 是一个多平台,多 OpenFlow 版本支持的开源 datapath,主要专注在性能和可扩展性上。https://github.com/bisdn/xdpd/blob/stable/README
从零开发的用户空间协议栈套件 mTCP
mTCP 是一个针对多核系统的高可扩展性的用户空间 TCP/IP 协议栈。https://github.com/eunyoung14/mtcp/blob/master/README
Mirage-Tcpip
mirage-tcpip 是一个针对 MirageOS 这种 “库操作系统” 而开发的一个用户态网络协议栈,开发的语言是 OCaml。https://github.com/mirage/mirage-tcpip
IwIP
IwIP 针对 RAM 平台的精简版的 TCP/IP 协议栈实现。http://git.savannah.gnu.org/cgit/lwip.git/tree/README
移植版的用户空间协议栈套件 Arrakis
针对多核系统的用户空间 OS,移植于 IwIP。https://github.com/UWNetworksLab/arrakis/blob/master/README_ARRAKIS
libuinet
用户空间的 TCP/IP 协议栈,移植于 FreeBSD。https://github.com/pkelsey/libuinet/blob/master/README
NUSE (libos)
一个基于 Linux 的库操作系统,移植于 Linux。https://github.com/libos-nuse/net-next-nuse/wiki/Quick-Start
OpenDP
一个针对 DPDK TCP/IP 协议栈的数据面,移植于 FreeBSD。https://github.com/opendp/dpdk-odp/wiki
OpenOnload
一个高性能的用户态协议栈,移植于 IwIP。http://www.openonload.org/download/openonload-201205-README.txt
OSv
一个针对虚拟机的开源操作系统。移植于 FreeBSD。https://github.com/cloudius-systems/osv/blob/master/README.md
Sandstorm
一个针对个人服务器安全的开源网络平台,移植于 FreeBSD。https://github.com/sandstorm-io/sandstorm/blob/master/README.md
总结 1、这篇文字的亮点在于总结了当前阶段业界出现的一些用户空间协议栈,对于文章标题提到的 NFV 在文中则只字未提,但其实意思也很明了了。用户空间的协议栈是随着硬件技术的发展,以及新鲜应用场景应运而生的,换句话说,对于像 NFV 这种对性能要求比较高的场景,采用用户态的协议栈是比较合适的。
2、文中是 2015 年写的,这意味着到现在为止,肯定出现了很多比上面总结还要多的方案,其中比较出名的有 SeaStar 和 腾讯开源的 F-Stack,后面找机会再进行详述,敬请期待吧。
PS:文章未经我允许,不得转载,否则后果自负。
–END–
欢迎扫👇的二维码关注我的微信公众号,后台回复「m」,可以获取往期所有技术博文推送,更多资料回复下列关键字获取。