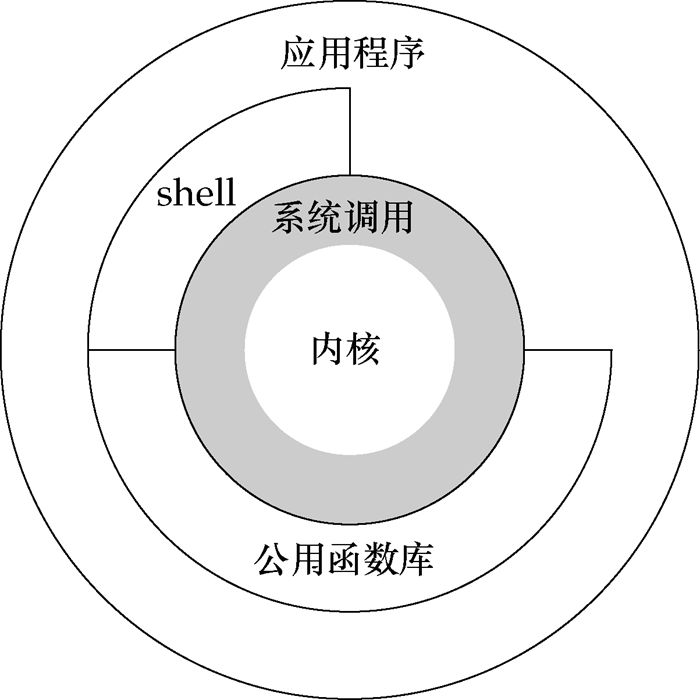
库函数正是为了将程序员从复杂的细节中解脱出来而提出的一种有效方法。它实现对系统调用的封装,将简单的业务逻辑接口呈现给用户,方便用户调用,从这个角度上看,库函数就像是组成汉字的“偏旁”。这样的一种组成方式极大增强了程序设计的灵活性,对于简单的操作,我们可以直接调用系统调用来访问资源,如“人”,对于复杂操作,我们借助于库函数来实现,如“仁”。显然,这样的库函数依据不同的标准也可以有不同的实现版本,如ISO C 标准库,POSIX 标准库等。
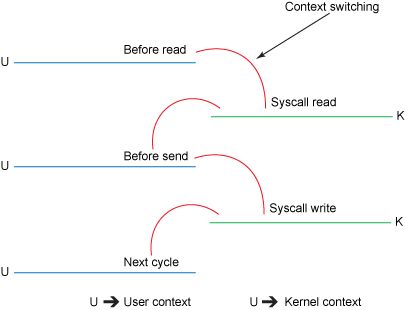
异常事件: 当 CPU 正在执行运行在用户态的程序时,突然发生某些预先不可知的异常事件,这个时候就会触发从当前用户态执行的进程转向内核态执行相关的异常事件,典型的如缺页异常。
外围设备的中断:当外围设备完成用户的请求操作后,会向 CPU 发出中断信号,此时,CPU 就会暂停执行下一条即将要执行的指令,转而去执行中断信号对应的处理程序,如果先前执行的指令是在用户态下,则自然就发生从用户态到内核态的转换。
注意: 系统调用的本质其实也是中断,相对于外围设备的硬中断,这种中断称为软中断,这是操作系统为用户特别开放的一种中断,如 Linux int 80h 中断。所以,从触发方式和效果上来看,这三种切换方式是完全一样的,都相当于是执行了一个中断响应的过程。但是从触发的对象来看,系统调用是进程主动请求切换的,而异常和硬中断则是被动的。
总结
本文仅是从宏观的角度去理解 Linux 用户态和内核态的设计,并没有去深究它们的具体实现方式。从实现上来看,必须要考虑到的一点我想就是性能问题,因为用户态和内核态之间的切换会消耗大量资源。
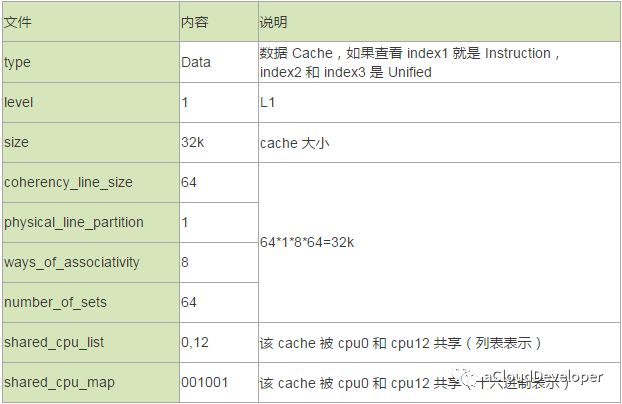
Linux # cat /proc/cpuinfo | grep "physical id" physical id : 0 physical id : 0 physical id : 0 physical id : 0 physical id : 1 physical id : 1 physical id : 1 physical id : 1
============================================================ Core and Socket Information (as reported by '/proc/cpuinfo') ============================================================
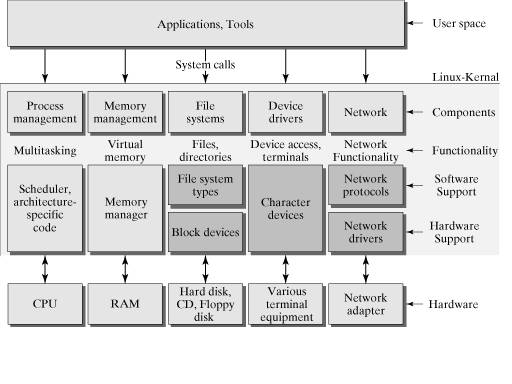
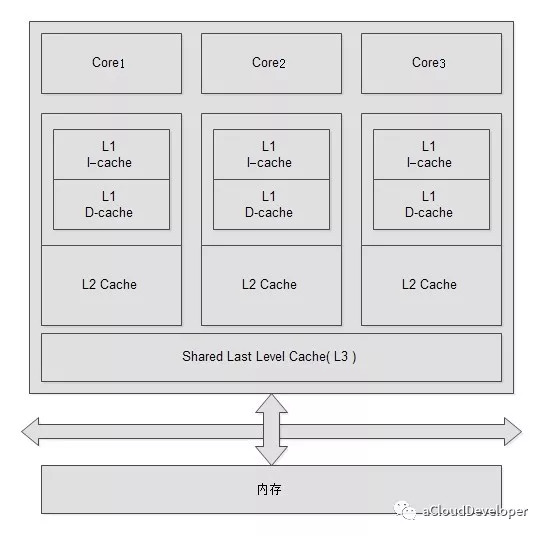
随着计算机技术(特别是以芯片为主的硬件技术)的快速发展,CPU 架构逐步从以前的单核时代进阶到如今的多核时代,在多核时代里,多颗 CPU 核心构成了一个小型的“微观世界”。每颗 CPU 各司其职,并与其他 CPU 交互,共同支撑起了一个“物理世界”。从这个意义上来看,我们更愿意称这样的“微观世界”为 CPU 拓扑,就像一个物理网络一样,各个网络节点通过拓扑关系建立起连接来支撑起整个通信系统。
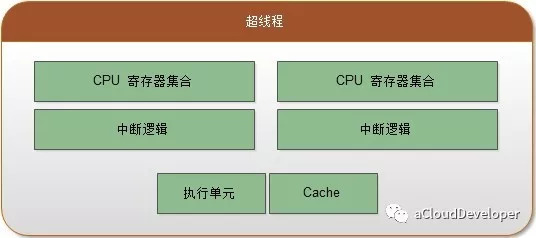
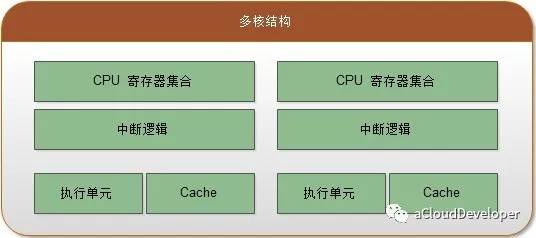
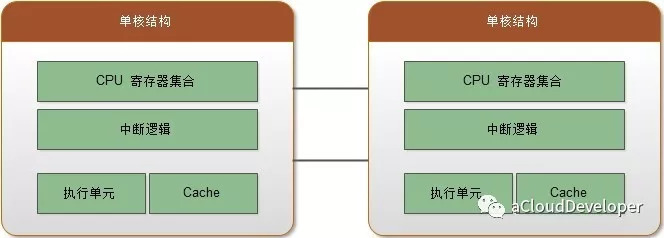
单核 or 多核 or 多 CPU or 超线程 ?
在单核时代,为了提升 CPU 的处理能力,普遍的做法是提高 CPU 的主频率,但一味地提高频率对于 CPU 的功耗也是影响很大的(CPU 的功耗正比于主频的三次方)。
如果说前面咱们讨论的是 CPU 内部的“微观世界”,那么本节将跳出来,探讨一个系统级的“宏观世界”。
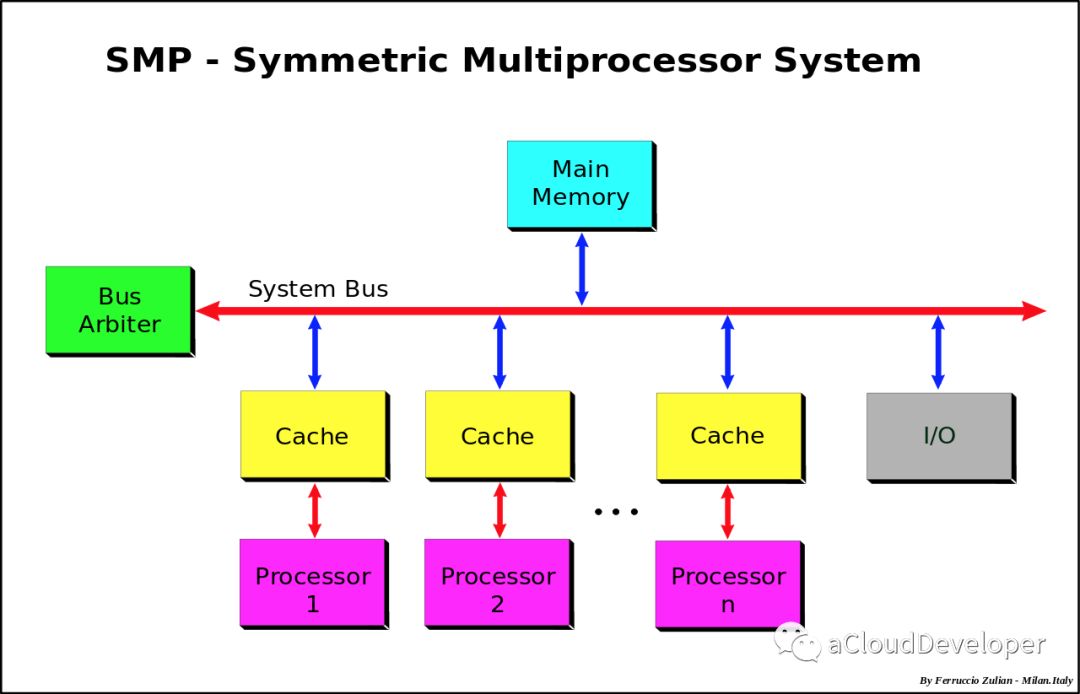
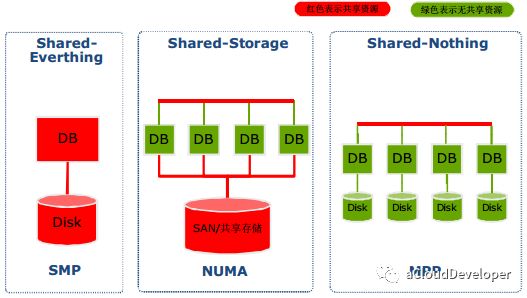
首先是 SMP,对称多处理器系统,指的是一种多个 CPU 处理器共享资源的电脑硬件架构,其中,每个 CPU 没有主从之分,地位平等,它们共享相同的物理资源,包括总线、内存、IO、操作系统等。每个 CPU 访问内存所用时间都是相同的,因此这种系统也被称为一致存储访问结构(UMA,Uniform Memory Access)。
ls /sys/devices/system/node/ # 如果只看到一个 node0 那就是 SMP 架构
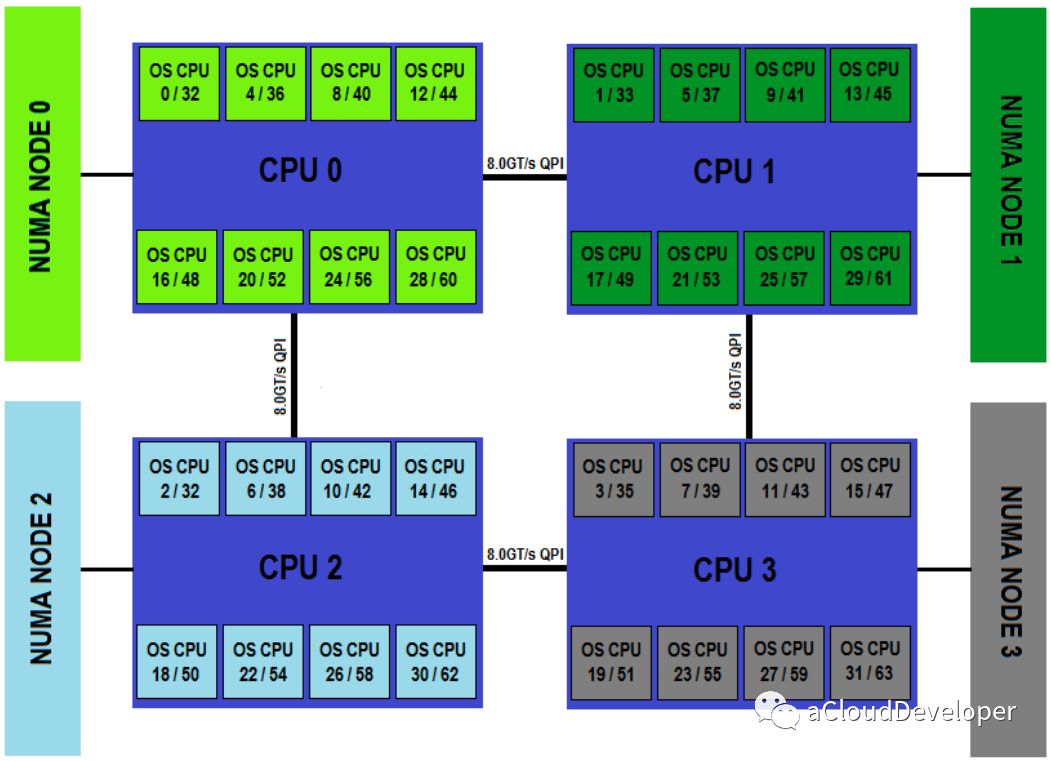
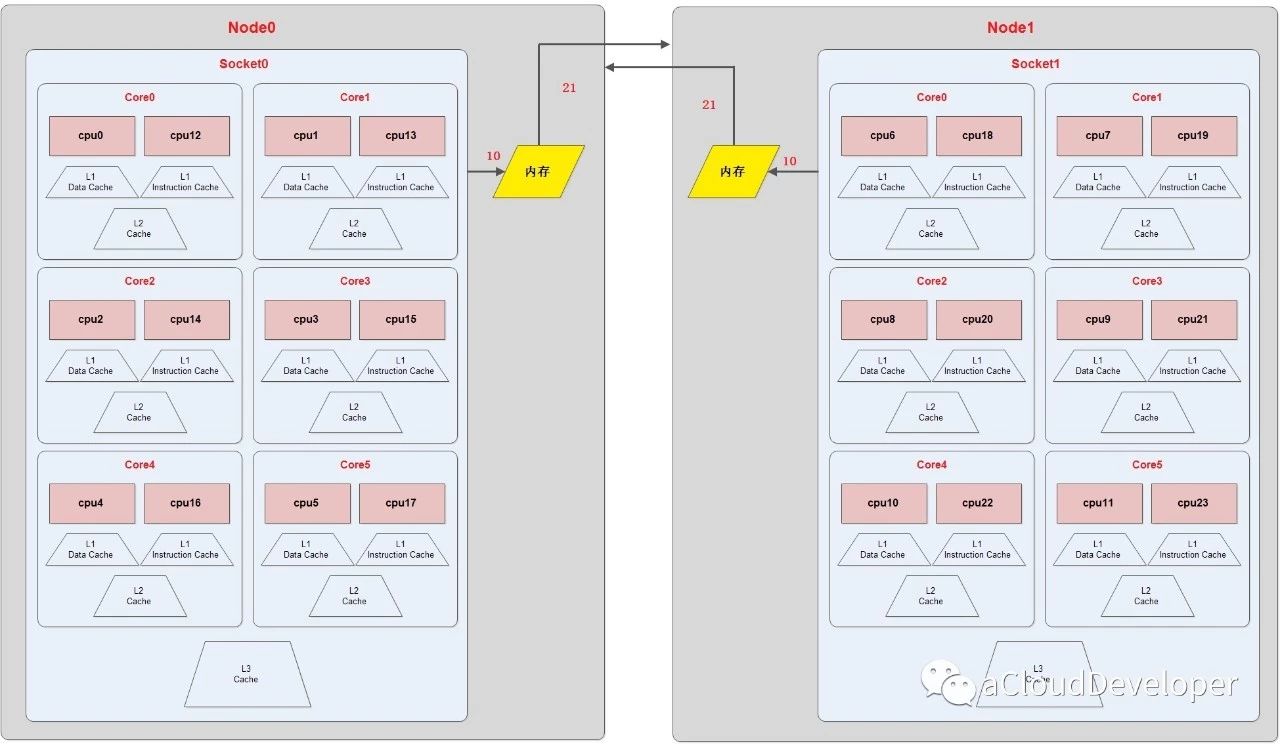
为了应对大规模的系统要求(特别是云计算环境),就研制出了 NUMA 结构,即非一致存储访问结构。
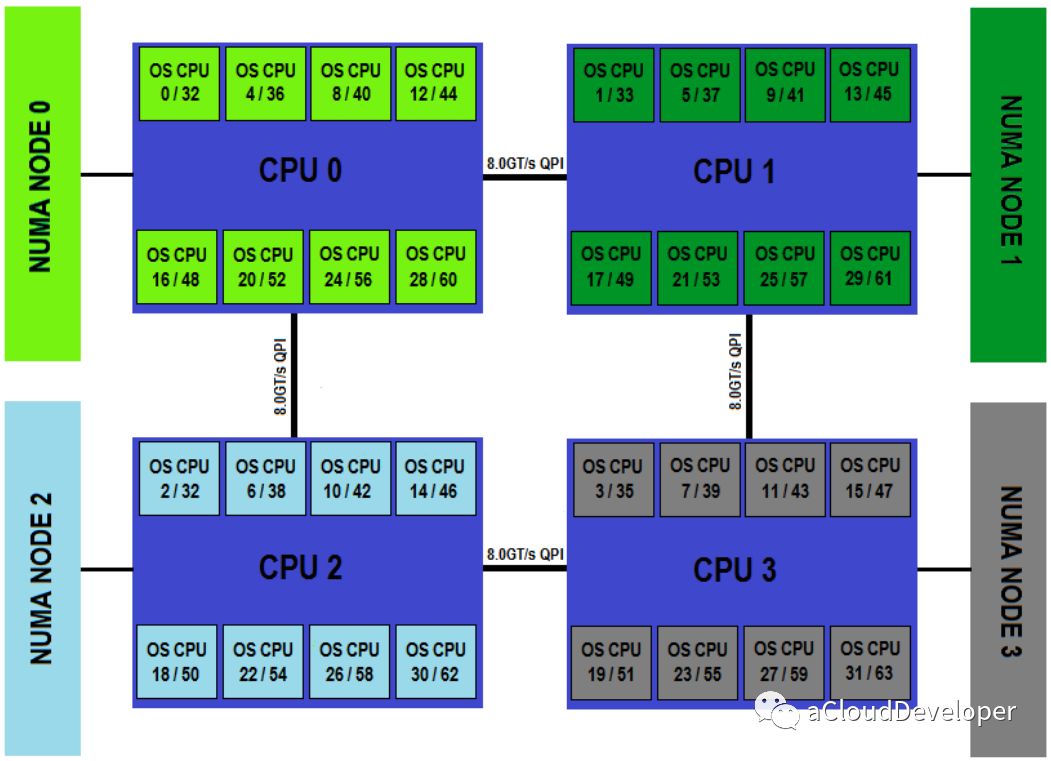
这种结构引入了 CPU 分组的概念,用 Node 来表示,一个 Node 可能包含多个物理 CPU 封装,从而包含多个 CPU 物理核心。每个 Node 有自己独立的资源,包括内存、IO 等。每个 Node 之间可以通过互联模块总线(QPI)进行通信,所以,也就意味着每个 Node 上的 CPU 都可以访问到整个系统中的所有内存,但很显然,访问远端 Node 的内存比访问本地内存要耗时很多,这也是 NUMA 架构的问题所在,我们在基于 NUMA 架构开发上层应用程序要尽可能避免跨 Node 内存访问。
NUMA 架构在 SMP 架构的基础上通过分组的方式增强了可扩展性,但从性能上看,随着 CPU 数量的增加,并不能线性增加系统性能,原因就在于跨 Node 内存访问的问题。所以,一般 NUMA 架构最多支持几百个 CPU 就不错了。
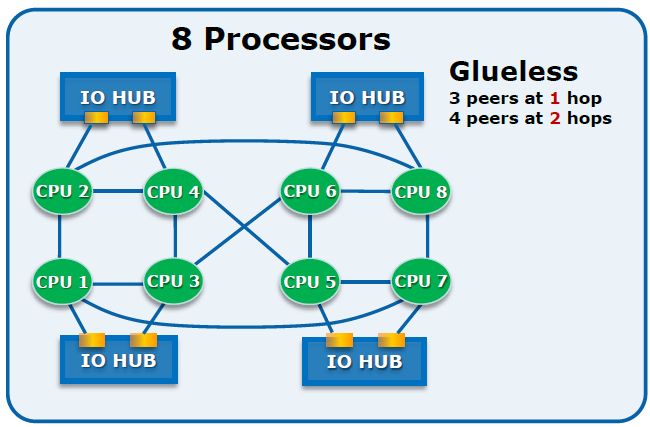
但对于很多大型计算密集型的系统来说,NUMA 显然有些吃力,所以,后来又出现了 MPP 架构,即海量并行处理架构。这种架构也有分组的概念,但和 NUMA 不同的是,它不存在异地内存访问的问题,每个分组内的 CPU 都有自己本地的内存、IO,并且不与其他 CPU 共享,是一种完全无共享的架构,因此它的扩展性最好,可以支持多达数千个 CPU 的量级。